Zoologie des fonctions d'activation
Sigmoid, tanh, ReLU, Swish, ELU… Une vraie zoologie de fonctions d’activation apparues depuis une dizaine d’années. Mais laquelle choisir ? Pour quel type de couche ? De réseaux ? De données… En préparant le cours Earth Data Science, j’avais besoin de faire le point sur le sujet. Quels sont les avantages, les défauts de chacune.
1. Propriétés mathématiques
Les fonctions d’activation sont au cœur de ce qui rend les réseaux de neurones capables d’apprendre des représentations non linéaires. Si on ne les avait pas, empiler des couches linéaires reviendrait à n’avoir qu’une seule transformation linéaire — un perceptron multicouche se réduirait à une régression linéaire, quelle que soit sa profondeur. Mais il faut répondre à quelques exigeances mathématiques.
1.1 Continuité et dérivabilité
L’entraînement par descente de gradient stochastique (SGD) repose sur la rétropropagation, qui calcule le gradient de la loss couche par couche en remontant du réseau vers l’entrée. Cela impose que chaque fonction d’activation soit différentiable — ou au moins différentiable presque partout*.
Preque partout ? Si je prend l’exemple de la fonction
ReLU, elle n’est pas dérivable en $x=0$, mais ce cas ne se produit que sur un seul point — on dit queReLUest dérivable presque partout. Un point isolé ne contribue pas au calcul du gradient, et la rétropropagation fonctionne sans problème.
1.2 Vanishing gradient — saturation
Une fonction sature quand sa dérivée tend vers 0 pour $\lvert x \lvert\gg 0$. Dans un réseau de $L$ couches, le gradient de la loss par rapport aux poids de la première couche contient un produit de $L$ dérivées. Si chaque dérivée est inférieure à $\frac{1}{4}$ (comme pour Sigmoid), ce produit s’effondre exponentiellement — c’est le vanishing gradient problem (Hochreiter, 1991 ; Bengio et al., 1994).
1.3 Exploding gradient
Symétriquement, si les dérivées dépassent systématiquement 1, les gradients croissent exponentiellement couche après couche. Ce phénomène est souvent traité par gradient clipping ou BatchNorm, mais le choix de la fonction d’activation y contribue.
1.4 Centrage autour de zéro
Si les activations sont toutes positives (Sigmoid, ReLU), les gradients des poids d’une même couche sont tous du même signe à chaque pas. La mise à jour se fait alors en zigzag dans l’espace des paramètres, ce qui ralentit la convergence. Une activation centrée autour de 0 (tanh) atténue ce problème.
1.5 Coût en calcul
max(0, x) est une simple comparaison. Une exponentielle est bien plus coûteuse. Sur des réseaux larges entraînés sur GPU, cet écart peut devenir mesurable.
2. Quelques fonctions d’activation
Dans cette partie, on va passer quelques fonctions d’activation en revue. Comme vous pouvez l’imaginer, la liste est loin d’être exhaustive. Si jamais vous en voulez plus, je vous propose la lecture de l’article (Ramachandran et al., 2017)
Petite figure de synthèse
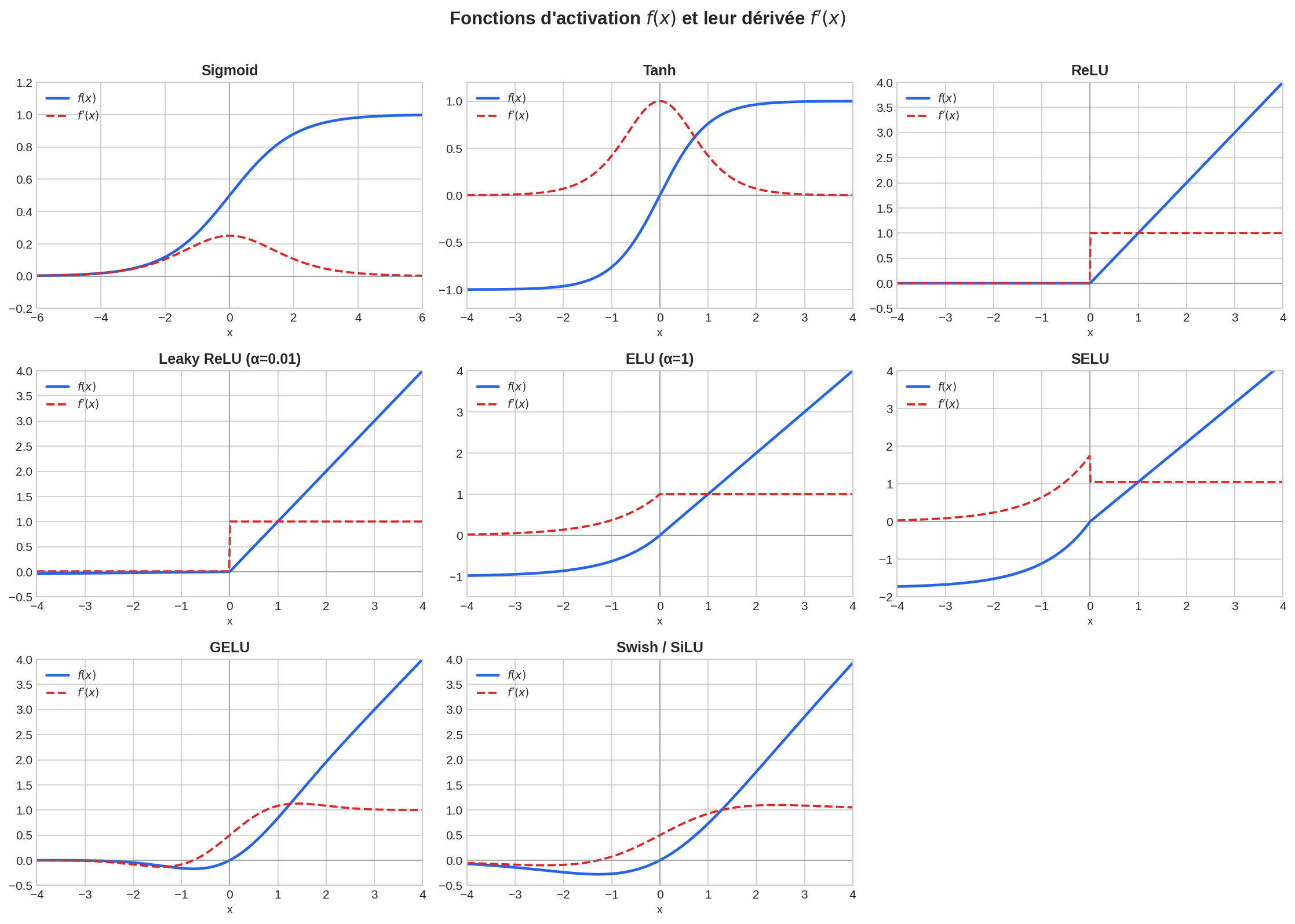
Sigmoid (logistique)
\[\sigma(x) = \frac{1}{1 + e^{-x}}, \qquad \sigma'(x) = \sigma(x)(1 - \sigma(x)) \leq \frac{1}{4}\]| Plage | $C^\infty$ | Zero-centered | Saturation | Coût |
|---|---|---|---|---|
| $(0, 1)$ | ✓ | ✗ | Oui | Moyen |
Historiquement omniprésente, elle souffre d’un vanishing gradient sévère (dérivée max $= \frac{1}{4}$) et d’une sortie systématiquement positive. Déconseillée dans les couches cachées depuis l’avènement de ReLU. Usage restant : sortie pour la classification binaire.
Tanh
\[\tanh(x) = 2\sigma(2x) - 1, \qquad \tanh'(x) = 1 - \tanh^2(x) \leq 1\]| Plage | $C^\infty$ | Zero-centered | Saturation | Coût |
|---|---|---|---|---|
| $(-1, 1)$ | ✓ | ✓ | Oui | Moyen |
Strictement supérieure à Sigmoid grâce au centrage en 0, mais elle sature également. Utilisée dans les cellules récurrentes (LSTM, GRU) et comme activation des gates.
Softmax
\[\text{Softmax}(\mathbf{x})_i = \frac{e^{x_i}}{\sum_j e^{x_j}}\]Pas une activation scalaire — elle opère sur un vecteur et produit une distribution de probabilités normalisée. Fondamentale comme couche de sortie pour la classification multiclasse. En pratique, on calcule $\text{Softmax}(\mathbf{x} - \max_j x_j)$ pour éviter les overflows numériques.
ReLU
\[\text{ReLU}(x) = \max(0, x), \qquad \text{ReLU}'(x) = \mathbf{1}_{x > 0}\]| Plage | $C^0$ (non $C^1$ en 0) | Zero-centered | Saturation | Coût |
|---|---|---|---|---|
| $[0, +\infty)$ | ✓ | ✗ | Non (côté +) | Très faible |
ReLU a démocratisé l’entraînement des réseaux profonds (Nair & Hinton, 2010) par sa simplicité et l’absence de saturation côté positif. Mais deux défauts principaux :
- Dying ReLU : un neurone recevant systématiquement des préactivations négatives a un gradient nul — il ne se met plus jamais à jour. Un taux d’apprentissage trop élevé peut “tuer” une fraction significative des neurones.
- Non zero-centered et non bornée côté positif.
Elle reste le point de départ par défaut pour la majorité des architectures.
Leaky ReLU
\[\text{LeakyReLU}(x) = \begin{cases} x & x > 0 \\ \alpha x & x \leq 0 \end{cases}, \quad \alpha \approx 0.01 \text{ (fixe)}\]Résout le dying ReLU en maintenant un gradient non nul côté négatif. Simple et efficace, bien que le gain sur ReLU ne soit pas toujours significatif.
PReLU (He et al., 2015) : même formule, mais $\alpha$ est appris pendant l’entraînement. Ajoute des paramètres ; risque de surapprentissage sur petits datasets.
ELU
\[\text{ELU}(x) = \begin{cases} x & x > 0 \\ \alpha(e^x - 1) & x \leq 0 \end{cases}, \quad \alpha = 1 \text{ typiquement}\](Clevert et al., 2016)
| Plage | $C^1$ | Zero-centered | Saturation | Coût |
|---|---|---|---|---|
| $(-\alpha, +\infty)$ | ✓ | Quasi | Partielle ($x \to -\infty$) | Moyen |
La dérivée est continue en 0 (contrairement à ReLU), ce qui lisse la transition. Les activations ont une moyenne plus proche de 0, ce qui atténue le problème de centrage. Coût légèrement supérieur à ReLU (une exponentielle pour $x < 0$).
SELU
\[\text{SELU}(x) = \lambda \begin{cases} x & x > 0 \\ \alpha(e^x - 1) & x \leq 0 \end{cases}\]avec $\lambda \approx 1.0507$, $\alpha \approx 1.6733$ (valeurs dérivées analytiquement). (Klambauer et al., 2017)
Propriété clé : avec l’initialisation LeCun normal et des couches entièrement connectées, SELU est auto-normalisante — les activations convergent vers une moyenne nulle et une variance unité couche après couche, sans normalisation. Cette propriété est fragile : elle ne s’applique pas aux CNN ni avec le dropout standard.
GELU
\[\text{GELU}(x) = x \cdot \Phi(x) = x \cdot \frac{1}{2}\!\left[1 + \operatorname{erf}\!\left(\frac{x}{\sqrt{2}}\right)\right]\]où $\Phi$ est la CDF (Cumulative Distribution Function) de la loi normale normale.
| Plage | $C^\infty$ | Zero-centered | Saturation | Coût |
|---|---|---|---|---|
| $\approx(-0.17, +\infty)$ | ✓ | Quasi | Non | Élevé |
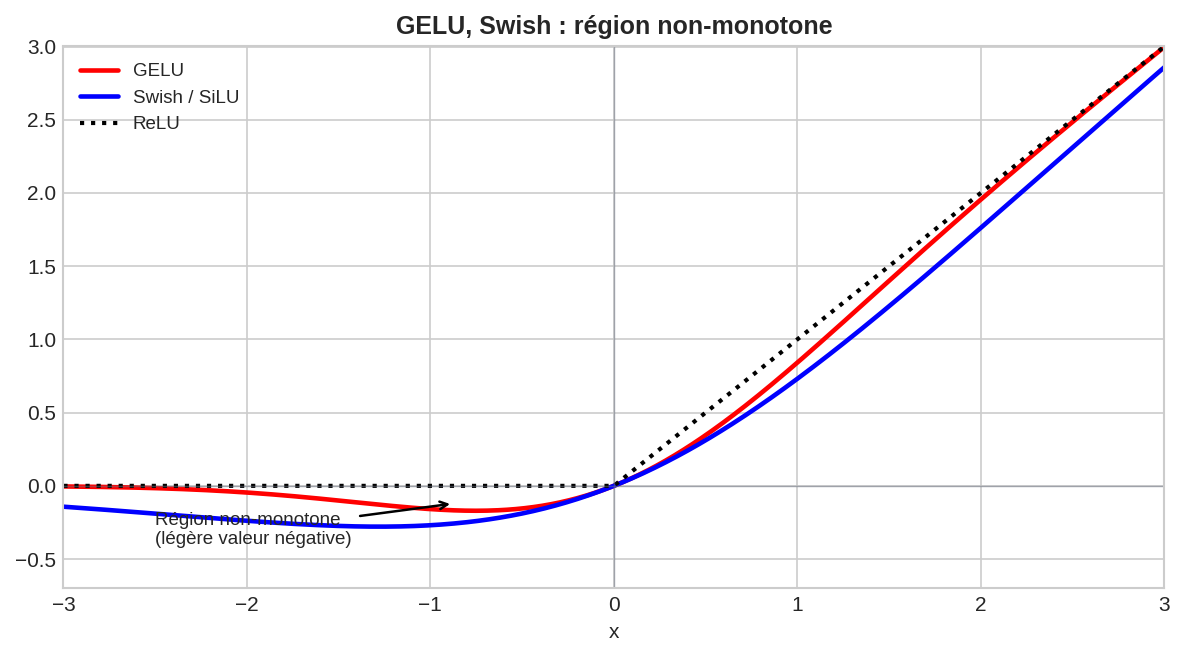
GELU peut être vue comme un gate stochastique : l’entrée $x$ est pondérée par la probabilité qu’elle dépasse un bruit gaussien. Les entrées fortement positives passent intégralement, les négatives sont atténuées de façon lisse. Non-monotone : un léger creux existe pour $x \in (-\approx 0.75, 0)$.
Swish / SiLU
\[\text{Swish}(x) = x \cdot \sigma(x) = \frac{x}{1 + e^{-x}}\](Ramachandran et al., 2017)
SiLU (Sigmoid Linear Unit) est le nom PyTorch de la même fonction ($\beta = 1$). Non-monotone, lisse ($C^\infty$), non bornée supérieurement. Découverte par recherche automatique d’architectures (NAS + reinforcement learning) sur un espace de fonctions composées d’opérateurs unaires et binaires.
3. Tableau de synthèse
| Fonction | Plage | Dérivée continue | Zero-centered | Saturation | Dying | Coût de calcul |
|---|---|---|---|---|---|---|
| Sigmoid | $(0,1)$ | ✓ ($C^\infty$) | ✗ | Oui | Non | Moyen |
| Tanh | $(-1,1)$ | ✓ ($C^\infty$) | ✓ | Oui | Non | Moyen |
| ReLU | $[0,+\infty)$ | ✗ (saut en 0) | ✗ | Non | Oui | Très faible |
| Leaky ReLU | $\mathbb{R}$ | ✗ (saut en 0) | ✗ | Non | Non | Très faible |
| ELU | $(-1,+\infty)$ | ✓ ($C^\infty$) | Quasi | Partielle | Non | Moyen |
| SELU | $\mathbb{R}$ | ✓ ($C^\infty$) | ✓ | Partielle | Non | Moyen |
| GELU | $\approx(-0.17,+\infty)$ | ✓ ($C^\infty$) | Quasi | Non | Non | Élevé |
| Swish/SiLU | $\mathbb{R}$ | ✓ ($C^\infty$) | Quasi | Non | Non | Moyen |
4. Tentative de guide de sélection pratique
Ce guide synthétise les conventions établies dans les papiers “fondateurs” de chaque architecture, ainsi que les recommandations de la littérature de survey (Apicella et al., 2021).
Selon la couche
Couche de sortie :
- Classification binaire → Sigmoid
- Classification multiclasse → Softmax
- Régression → Identité (aucune activation)
- Sortie bornée → Sigmoid ($[0,1]$) ou Tanh ($[-1,1]$)
Couches cachées :
- Réseau profond général (MLP, CNN) → ReLU (point de départ)
- Dying ReLU observé → Leaky ReLU ou ELU
- MLP profond sans normalisation → SELU (+ initialisation LeCun)
- Architecture Transformer → GELU
- CNN haute performance (EfficientNet, ConvNeXt…) → Swish/SiLU (Ramachandran et al., 2017)
Selon l’architecture
| Architecture | Recommandation | Référence |
|---|---|---|
| MLP classique | ReLU ou ELU | Nair & Hinton (2010), Clevert et al. (2016) |
| CNN (baseline) | ReLU | Nair & Hinton (2010) |
| CNN haute performance (EfficientNet, ConvNeXt…) | Swish/SiLU | Tan & Le (2019) — EfficientNet |
| Transformer (encodeur) | GELU | Devlin et al. (2019) — BERT |
| Transformer (décodeur) | GELU ou SiLU | Brown et al. (2020) — GPT-3 |
| LSTM / GRU | Tanh (état), Sigmoid (gates) | Hochreiter & Schmidhuber (1997) |
| GAN (discriminateur) | Leaky ReLU | Radford et al. (2016) — DCGAN |
| Réseau sans normalisation | SELU | Klambauer et al. (2017) |
Selon la nature des données
Le choix de la fonction d’activation reste principalement guidé par l’architecture et la tâche, mais la nature des données peut orienter à la marge :
- Données bruitées ou avec outliers : les activations lisses (ELU, GELU) sont plus robustes, le gradient binaire de ReLU pouvant amplifier les discontinuités.
- Petit dataset : éviter PReLU (paramètres supplémentaires) ; préférer ReLU ou ELU avec régularisation.
- Données normalisées (BatchNorm ou LayerNorm) : la propriété zero-centered devient moins critique — ReLU suffit dans la plupart des cas.
6. Référence rapide : PyTorch et Keras/TensorFlow
Voilà les fonctions correspondantes en Keras/TF et Pytorch. EDIT (2023) : maintenant que je n’utilise plus TF, j’ai ajouté la colonne Pytorch.
| Fonction | PyTorch (torch.nn) | PyTorch fonctionnel (torch.nn.functional) | Keras / TensorFlow |
|---|---|---|---|
| Sigmoid | nn.Sigmoid() | F.sigmoid(x) | 'sigmoid' |
| Tanh | nn.Tanh() | F.tanh(x) | 'tanh' |
| Softmax | nn.Softmax(dim=1) | F.softmax(x, dim=1) | 'softmax' |
| ReLU | nn.ReLU() | F.relu(x) | 'relu' |
| Leaky ReLU | nn.LeakyReLU(0.01) | F.leaky_relu(x, 0.01) | keras.layers.LeakyReLU(0.01) |
| PReLU | nn.PReLU() | — | keras.layers.PReLU() |
| ELU | nn.ELU() | F.elu(x) | 'elu' |
| SELU | nn.SELU() | F.selu(x) | 'selu' |
| GELU | nn.GELU() | F.gelu(x) | 'gelu' |
| Swish / SiLU | nn.SiLU() | F.silu(x) | 'swish' |
7. Conclusion
La “prolifération” des fonctions d’activation reflète la diversité des compromis à opérer : vitesse de calcul, propriétés de gradient, stabilité, compatibilité avec les architectures…
En pratique, ReLU reste le point de départ pour la majorité des réseaux. GELU est devenu le standard des Transformers depuis BERT (Devlin et al., 2019). Tanh et Sigmoid survivent dans leurs niches (sorties, cellules récurrentes).
Ce domaine reste actif. Ramachandran et al. (2017) ont montré, via une recherche automatique sur un espace de plusieurs milliers de fonctions composées, que Swish pouvait systématiquement surpasser ReLU sur des réseaux profonds — tout en notant que les gains restaient inconsistants selon les architectures et les tâches.
On retiendra qu’il n’existe pas de choix universellement optimal : Le mieux, pour commencer, c’est d’utiliser la convention établie pour l’architecture cible (celle décrite dans la littérature), et de valider empiriquement tout écart.
Quelques références
- Apicella, A., et al.. (2021). A survey on modern trainable activation functions. Neural Networks, 138, 14–32. arXiv:2005.00817
- Ramachandran, et al. (2017). Searching for activation functions. arXiv:1710.05941
- Bengio, et al. (1994). Learning long-term dependencies with gradient descent is difficult. IEEE Transactions on Neural Networks, 5(2), 157–166.
- Clevert et al. (2016). Fast and accurate deep network learning by exponential linear units (ELUs). ICLR 2016. arXiv:1511.07289
- He, et al. (2015). Delving deep into rectifiers. ICCV 2015. arXiv:1502.01852
- Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735–1780.
- Klambauer, G., Unterthiner, T., Mayr, A., & Hochreiter, S. (2017). Self-normalizing neural networks. NeurIPS 2017. arXiv:1706.02515
- Nair, V., & Hinton, G. E. (2010). Rectified linear units improve restricted Boltzmann machines. ICML 2010.