Convolutions et gradient vanishing. (DDPM 2)
Introduction
Dans ce deuxième billet, j’abord un peu les briques mathématiques et architecturales qui permettent de construire le réseau de débruitage du DDPM. Je démarre par la convolution, puis j’enchaine sur le problème du gradient vanishing qui limite les réseaux profonds, et la solution élégante que propose ResNet.
1. Pourquoi des convolutions ?
Lorsqu’on traite une image astro., le signal physique est local : le profil de brillance, le gradient de couleur, la texture d’une région s’expriment sur quelques dizaines de pixels. Un réseau entièrement connecté (fully connected network, FCN) traiterait chaque pixel indépendamment, ignorant toute cohérence spatiale, et nécessiterait un nombre de paramètres prohibitif, de l’ordre de $H \times W \times C$ par neurone, soit plusieurs millions pour une image 64×64×3 comme dans mon cas.
Une couche convolutive résout les deux problèmes simultanément. Elle applique un filtre $\mathbf{W} \in \mathbb{R}^{k \times k}$ qui se déplace sur l’image par fenêtre glissante, extrayant des motifs locaux (avec un hypothèse d’invariance par translation) :
\[(\mathbf{x} \star \mathbf{W})[i,j] = \sum_{u=-\lfloor k/2 \rfloor}^{\lfloor k/2 \rfloor} \sum_{v=-\lfloor k/2 \rfloor}^{\lfloor k/2 \rfloor} \mathbf{x}[i+u,\, j+v]\; \mathbf{W}[u,v]\]En pratique, on empile $C_\text{out}$ filtres différents, produisant $C_\text{out}$ cartes de caractéristiques (feature maps). Le nombre de paramètres d’une telle couche est $C_\text{in} \times C_\text{out} \times k^2$, indépendant de la résolution spatiale : un avantage décisif pour des images de grande taille.
Pour une image 64×64×3 et une couche convolutive 3×3 produisant 64 feature maps, le nombre de paramètres est $3 \times 64 \times 9 = 1\,728$, contre plusieurs millions pour une couche fully connected équivalente.
Cette réduction drastique du nombre de paramètres est la raison principale du succès des réseaux convolutifs et c’est ce qui a permis, dans les années 2010 de se lancer dans des réseaux de plus en plus profonds.
2. Le problème du gradient vanishing
Dès lors qu’on cherche à empiler de nombreuses couches convolutives pour apprendre des représentations de plus en plus abstraites, on se heurte à un obstacle fondamental : le gradient vanishing (disparition du gradient), identifié dès les années 1990 (Hochreiter 1991 ; Bengio et al. 1994). On trouvera une explication simplifiée dans le livre de Géron (2020).
2.1 Intuition mathématique
SI je note $\mathbf{h}^{(k)}$ l’activation de la couche $k$, avec $\mathbf{h}^{(0)} = \mathbf{x}$ l’entrée du réseau et $\mathbf{h}^{(L)}$ sa sortie. Lors de la rétropropagation, le gradient de la loss $\mathcal{L}$ par rapport aux paramètres d’une couche $\ell$ s’écrit comme un produit de Jacobiens :
\[\frac{\partial \mathcal{L}}{\partial \mathbf{W}^{(\ell)}} = \frac{\partial \mathcal{L}}{\partial \mathbf{h}^{(L)}} \cdot \prod_{k=\ell}^{L-1} \frac{\partial \mathbf{h}^{(k+1)}}{\partial \mathbf{h}^{(k)}} \cdot \frac{\partial \mathbf{h}^{(\ell)}}{\partial \mathbf{W}^{(\ell)}}\]Si chaque Jacobien a une norme spectrale* inférieure à 1 — ce qui est fréquent avec des activations saturantes comme $\texttt{sigmoid}$ ou $\texttt{tanh}$ dont les dérivées sont au plus $\frac{1}{4}$ et $1$ respectivement. Le produit décroît exponentiellement avec la profondeur $L - \ell$. Les couches proches de l’entrée reçoivent un gradient quasi nul et cessent d’apprendre. C’est ça la disparition du gradient, le malédiction de la grande dimension comme le nomme Stéphane Mallat
2.2 Solutions partielles avant ResNet
Plusieurs palliatifs ont été proposés, sans résoudre le problème structurellement :
- ReLU (Nair & Hinton 2010) : élimine la saturation des activations pour les valeurs positives, mais n’empêche pas le vanishing pour les neurones à activation nulle (dying ReLU).
- Batch Normalization (Ioffe & Szegedy 2015) : normalise les activations intermédiaires, stabilise les gradients et permet d’utiliser des learning rates plus élevés. Efficace mais insuffisant au-delà d’une certaine profondeur.
- Initialisation soignée (Glorot & Bengio 2010 ; He et al. 2015) : calibre la variance des poids à l’initialisation pour maintenir la norme du gradient à travers les couches. Voir le livre de Géron également.
Ces techniques améliorent la situation mais ne la résolvent pas structurellement. Elles retardent l’apparition du problème mais ne l’évitent pas.
3. Les connexions résiduelles : le ResNet
He et al. (2016) proposent une solution élégante au gradient vanishing : plutôt qu’apprendre directement la transformation souhaitée $\mathcal{H}(\mathbf{x})$, on apprend la résiduelle $\mathcal{F}(\mathbf{x}) = \mathcal{H}(\mathbf{x}) - \mathbf{x}$. La sortie du bloc devient :
\[\boxed{\mathbf{y} = \mathcal{F}(\mathbf{x},\, \{\mathbf{W}_i\}) + \mathbf{x}}\]Le terme $+ \mathbf{x}$ est la connexion résiduelle (skip connection) : il court-circuite les couches intermédiaires en additionnant directement l’entrée à la sortie du bloc.
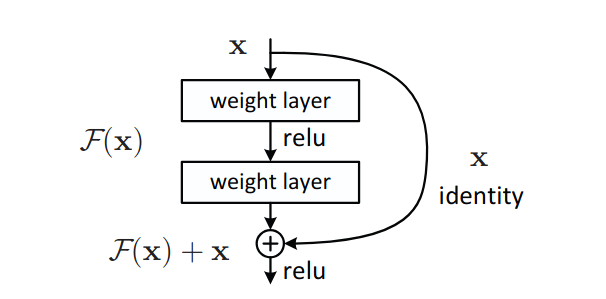
3.1 Pourquoi ça résout le problème
Le gradient de la loss par rapport à l’entrée $\mathbf{x}$ du bloc vaut :
\[\frac{\partial \mathcal{L}}{\partial \mathbf{x}} = \frac{\partial \mathcal{L}}{\partial \mathbf{y}} \cdot \left(1 + \frac{\partial \mathcal{F}}{\partial \mathbf{x}}\right)\]Le terme $1$ garantit qu’il existe toujours un chemin de gradient direct depuis la sortie vers l’entrée, quelle que soit la profondeur du réseau. Et même si $\partial \mathcal{F}/\partial \mathbf{x}$ devient petit, le gradient ne disparaît pas pour autant. Il est au minimum égal au gradient de la couche suivante.
Intuitivement : si un bloc résiduel n’apprend rien ($\mathcal{F}(\mathbf{x}) \to \mathbf{0}$), il se comporte comme une identité. Le réseau peut donc ajouter des blocs sans risque de dégradation, ce qui a permis d’entraîner à l’époque, des réseaux de 152 couches (He et al. 2016), c’est le réseau ResNet-152
3.2 La projection 1×1 pour changer la dimension
Lorsque $\text{in_c} \neq \text{out_c}$, la connexion résiduelle $\mathbf{x} + \mathcal{F}(\mathbf{x})$ n’est pas dimensionnellement cohérente. He et al. (2016) proposent d’utiliser une convolution 1×1, aussi appelée projection, pour aligner les dimensions sans modifier la résolution spatiale :
\[\mathbf{y} = \mathcal{F}(\mathbf{x}) + \mathbf{W}_s \mathbf{x} \qquad \text{avec } \mathbf{W}_s \in \mathbb{R}^{C_\text{out} \times C_\text{in} \times 1 \times 1}\]Lorsque $\text{in_c} = \text{out_c}$, la projection est simplement l’identité.
4. Normalisation : BatchNorm, LayerNorm, GroupNorm…
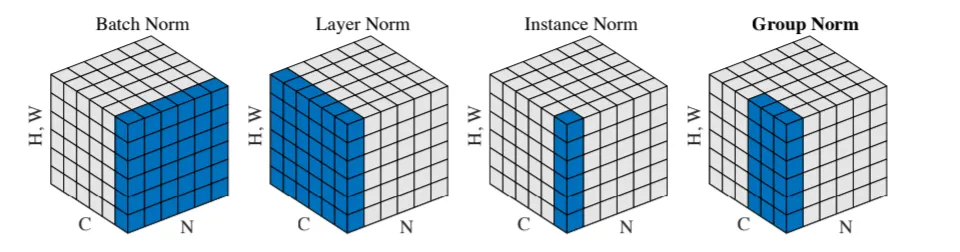
La normalisation est une composante essentielle des réseaux profonds modernes. Toutes les méthodes calculent une moyenne $\mu$ et un écart-type $\sigma$ sur un sous-ensemble des activations, puis normalisent : $\hat{x} = (x - \mu) / \sigma$. Ce qui les distingue, c’est sur quelles dimensions ce calcul est effectué, pour un tenseur de forme $(N, C, H, W)$ :
-
BatchNorm (Ioffe & Szegedy 2015) : normalise sur $(N, H, W)$ : statistique partagée entre tous les exemples du batch pour chaque canal. Efficace avec de grands batchs, instable avec de petits batchs ou des batchs hétérogènes.
-
LayerNorm (Ba et al. 2016) : normalise sur $(C, H, W)$ : statistique calculée indépendamment pour chaque exemple. Aucune dépendance au batch.
-
GroupNorm (Wu & He 2018) : normalise sur des groupes de canaux et $(H, W)$ : divise les $C$ canaux en $G$ groupes et normalise chaque groupe indépendamment. Stable quelle que soit la taille du batch. Cas limite : $G = 1$ redonne LayerNorm, $G = C$ donne InstanceNorm.
Dans le contexte du DDPM, chaque image est conditionnée par son propre pas de temps $t$, ce qui rend la statistique de batch hétérogène. GroupNorm(32) est le choix de Ho et al. (2020) dans leur implémentation de référence : et celui que j’ai retenu.
5. L’activation SiLU
L’activation utilisée dans notre ResBlock est la SiLU (Sigmoid Linear Unit, aussi appelée Swish) :
\[f(x) = x \cdot \sigma(x) = \frac{x}{1 + e^{-x}}\]introduite par Ramachandran et al. (2017). Contrairement à la ReLU qui annule strictement les valeurs négatives, la SiLU est partout dérivable et laisse passer une fraction des activations négatives, produisant des gradients plus réguliers. Elle est couramment adoptée dans les réimplémentations de DDPM pour sa régularité numérique. Ho et al. (2020) n’en font pas mention explicitement dans leur papier original, mais c’est le choix de la majorité des implémentations de référence. J’ai fait un billet sur la zoologie des fonctions d’activations.
Références
-
Hochreiter, S. (1991). Untersuchungen zu dynamischen neuronalen Netzen. Diplomarbeit, TU München.
-
Bengio, Y., Simard, P., & Frasconi, P. (1994). Learning Long-Term Dependencies with Gradient Descent is Difficult. IEEE Transactions on Neural Networks 5(2), 157–166.
-
Géron, A., Deep learning avec Keras et Tensorflow, mise en oeuvre et cas concrets, Dunod Editions, 2ème Ed. 2020
-
Nair, V., & Hinton, G. E. (2010). Rectified Linear Units Improve Restricted Boltzmann Machines. ICML 2010.
-
Glorot, X., & Bengio, Y. (2010). Understanding the Difficulty of Training Deep Feedforward Neural Networks. AISTATS 2010.
-
He, K., Zhang, X., Ren, S., & Sun, J. (2015). Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. ICCV 2015. arXiv:1502.01852
-
Ioffe, S., & Szegedy, C. (2015). Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. ICML 2015. arXiv:1502.03167
-
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep Residual Learning for Image Recognition. CVPR 2016. arXiv:1512.03385
-
Ba, J. L., Kiros, J. R., & Hinton, G. E. (2016). Layer Normalization. arXiv:1607.06450
-
Ramachandran, P., Zoph, B., & Le, Q. V. (2017). Searching for Activation Functions. arXiv:1710.05941
-
Wu, Y., & He, K. (2018). Group Normalization. ECCV 2018. arXiv:1803.08494
-
Ho, J., Jain, A., & Abbeel, P. (2020). Denoising Diffusion Probabilistic Models. NeurIPS 2020. arXiv:2006.11239
Enjoy Reading This Article?
Here are some more articles you might like to read next: