Pourquoi des modèles génératifs pour les galaxies ? (DDPM 1)
Introduction
Dans ce billet et dans les quelques suivants, je vais aborder la notion de modèles de diffusion en Deep learning. C’est un domaine très fécond que j’ai décidé d’explorer afin de générer des images astronomiques réalistes. Comme on va le voir, il y a pléthore de modèle génératif et j’ai décidé de me concentrer sur la famille des DDPM et assimilé.
Afin de rendre mon travail réaliste, j’ai, dans un premier temps, commencé par travailler avec un célèbre dataset appellé Galaxy Zoo que je vais décrire dans la première partie.
Ensuite, je vais essayer de discuter des raisons qui m’ont poussé à développer les modèles génératifs, tout en pointant les limites liées aux spécificités des images astronomiques.
Ce billet (comme les autres) a été réédité, corrigé et complété pour rester à jour.
1. Galaxy Zoo 2 : classifier la morphologie à grande échelle
Le catalogue Galaxy Zoo 2 (GZ2, Willett et al. 2013 ; Hart et al. 2016), c’est le résultat d’un projet de science citoyenne dans lequel des centaines de milliers de volontaires ont classé visuellement des centaines de milliers de galaxies issues du Sloan Digital Sky Survey (SDSS, York et al. 2000). Chaque galaxie a reçu une étiquette morphologique (spirale, elliptique, irrégulière, avec ou sans barre, etc.), à partir de réponses à un arbre de décision.
Le résultat est un catalogue de ~240 000 galaxies (images RGB, $64^2$ pixels) et des probabilités de classification par morphologie. C’est mon premier terrain de jeu pour mes modèles génératifs, en me concentrant sur les galaxies spirales.
2. Pourquoi un modèle génératif ?
Un modèle génératif apprend la distribution statistique $p(\mathbf{x})$ des images d’entraînement, de façon à pouvoir en fabriquer de nouvelles. Dans le contexte de la morphologie galactique, plusieurs applications sont motivantes :
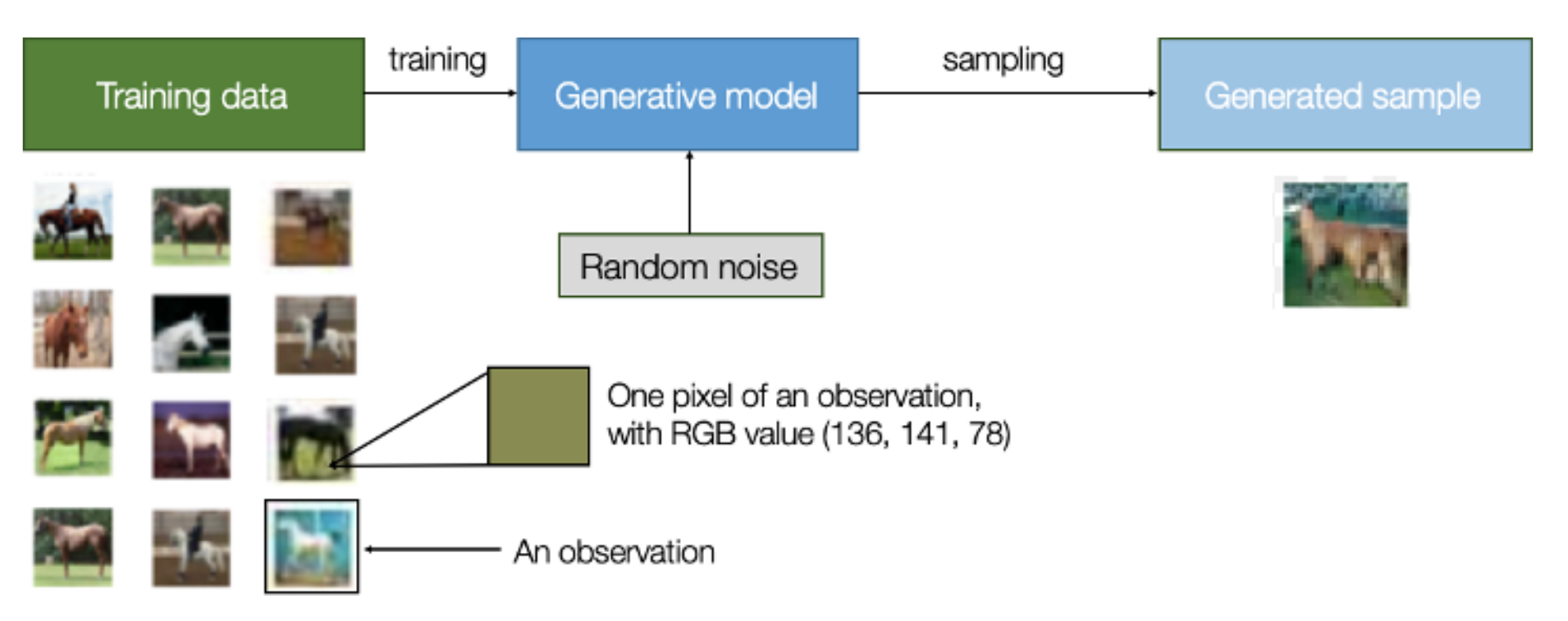
Augmentation de données. Les réseaux de classification souffrent du déséquilibre entre classes morphologiques. Générer des exemples synthétiques réalistes permet d’équilibrer le dataset sans avoir recours à de simples symétries ou rotations.
Exploration de l’espace morphologique. Un bon modèle génératif capture l’ensemble de la diversité morphologique : spirales serrées, ouvertes, barrées, en interaction. On peut explorer cet espace de manière continue, ce qui est impossible avec un catalogue discret.
Détection d’anomalies. En apprenant la distribution des galaxies “normales”, un modèle génératif peut signaler des objets atypiques dont la vraisemblance sous le modèle est faible ie. fusion de galaxies, artefacts d’imagerie, autres objets rares…
Simulation de futures observations. Des instruments comme le SKA (Square Kilometer Array) ou le Vera Rubin Observatory vont générer des volumes de données sans précédent. Des modèles génératifs entraînés sur des données existantes peuvent servir à simuler des populations réalistes pour préparer les pipelines d’analyse et les algorithmes d’identification de sources comme YOLO-CIANNA.
3. Panorama des approches génératives
Trois principales familles de modèles génératifs dominent la littérature :
Variational Autoencoders (VAE). Kingma & Welling (2013) proposent d’encoder les images dans un espace latent gaussien et de les reconstruire par un décodeur. Les VAE sont stables à l’entraînement mais produisent des images floues, car la loss MSE favorise la moyenne des modes plutôt que des échantillons nets.
Generative Adversarial Networks (GAN). Goodfellow et al. (2014) mettent en compétition un générateur et un discriminateur. Les GAN produisent des images très nettes mais sont difficiles à entraîner (instabilité, mode collapse) et leur couverture de la distribution réelle est souvent partielle.
Modèles de diffusion (DDPM). Ho et al. (2020) proposent d’apprendre à inverser un processus de bruitage gaussien progressif. Les modèles de diffusion sont stables à l’entraînement, couvrent bien la distribution réelle et produisent des échantillons de haute qualité, au prix d’un temps d’inférence plus long. C’est l’approche que j’ai retenue.
Il existe d’autres modèles comme les Autoregressive Models (PixelCNN, GPT…), les Normalizing Flows, les Energy-Based Models que je n’aborderai pas ici. On pourra se reporter au livre de David Foster Generative Deep Learning dont vous trouverez la référence en bas de ce billet.
4. Spécificités des images astronomiques
Les images de galaxies ne sont pas des images naturelles. Quatre propriétés les distinguent fondamentalement, avec des conséquences directes sur les choix d’implémentation pour tout modèle de deep learning.
4.1 La Point Spread Function (PSF)
La PSF (Point Spread Function ou “fonction d’étalement du point”) décrit la réponse impulsionnelle spatiale du système d’imagerie à une source ponctuelle (cf Wikipedia). Elle encode à la fois les aberrations optiques du télescope et les effets de turbulence atmosphérique (seeing). Pour les images SDSS, la médiane du seeing est de 1.32 arcseconde en bande r, ce qui correspond à une PSF approximativement gaussienne.
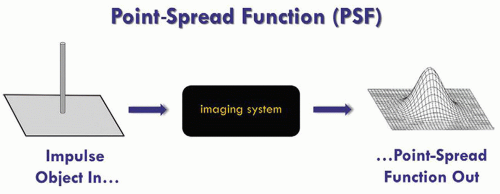
La PSF a deux conséquences importantes pour le deep learning. D’abord, elle corrèle spatialement les pixels voisins : deux pixels proches ne sont pas des mesures indépendantes du flux physique sous-jacent. Ensuite, elle est anisotrope : toute transformation géométrique appliquée à l’image modifie la forme apparente de la PSF. En particulier, une rotation à angle arbitraire nécessite une interpolation bilinéaire qui filtre les hautes fréquences spatiales et dégrade la PSF. C’est pourquoi plusieurs travaux de deep learning sur les images astronomiques se limitent aux rotations discrètes {0°,90°,180°,270°} (Flamary et al. 2022 ; Asensio Ramos et al. 2024). C’est le choix que j’ai également adopté dans mon processus d’augmentation d’image.
4.2 La dynamique logarithmique du flux
La brillance de surface des galaxies couvre plusieurs ordres de grandeur, du fond de ciel très sombre au noyau galactique très brillant (Binney & Merrifield, 1998). Cette dynamique est mal adaptée aux réseaux de neurones qui, généralement, opèrent sur des valeurs normalisées dans $[0, 1]$ : la quasi-totalité des pixels sont proches de 0, tandis qu’une poignée de pixels très brillants dominent la plage de valeurs.
La photométrie SDSS traite ce problème en utilisant des magnitudes asinh (Lupton, Gunn & Szalay, 1999), une transformation conçue pour se comporter comme la magnitude standard à haut rapport signal/bruit, mais rester bien définie aux faibles flux et aux valeurs négatives. La transformation asinh comprime la dynamique de manière logarithmique tout en restant définie en zéro.
Pour information, c’est fonction existe dans Astropy : documentation AsinhStretch
4.3 Le modèle de bruit CCD
Le bruit dans les images astronomiques n’est pas le bruit gaussien additif des images naturelles. Il résulte de la combinaison de plusieurs contributions physiques distinctes (on se reportera avec profit à Janesick (2001) - disponible en ligne) :
- Bruit de photons (shot noise) : Poissonnien, proportionnel à $\sqrt{N}$ où $N$ est le nombre de photons détectés. Dominant sur les sources brillantes.
- Bruit de lecture (read noise) : gaussien, introduit par l’électronique de lecture du CCD.
- Courant d’obscurité (dark current) : Poissonnien, dû à l’agitation thermique. Il peut être minimisé par refroidissement du détecteur.
- Fond de ciel : émission diffuse du ciel nocturne (raies d’émission atmosphériques, lumière zodiacale). S’ajoute au signal de la source et contribue au bruit de photons total.
- Rayons cosmiques : impacts de particules énergétiques qui saturent localement des pixels, produisant des artefacts impulsionnels.
Ce modèle de bruit, particulièrement complexe est à la fois gaussien et poissonien. L’hypothès de départ du processus forward des DDPM est justement que les images d’entrée ont un bruit gaussien isotrope. Gardons à l’esprit que cette hypothèse est une limitation connue des modèles de diffusion appliqués directement aux images astronomiques brutes.
4.4 Les artefacts de compression
Enfin, soulignons la spécification des images GZ2 qui sont distribuées au format JPEG, qui introduit des artefacts de compression en blocs 8×8 pixels non physiques. Ces artefacts sont présents dans l’ensemble du dataset et seront inévitablement appris par notre modèle génératif. Pour bien faire, il est préférable de travailler directement avec les données FITS brutes. Là aussi, il faut avoir en tête cette limitation.
Références
-
Willett, K. W., et al. (2013). Galaxy Zoo 2: detailed morphological classifications for 304 122 galaxies from the Sloan Digital Sky Survey. MNRAS 435, 2835. arXiv:1308.3496
-
Hart, R. E., et al. (2016). Galaxy Zoo 2: the fractions of bars, bulges, and other morphological features. MNRAS 461, 3663. arXiv:1607.01189
-
Foster, D., Generative Deep Learning: Teaching Machines To Paint, Write, Compose, and Play, O’Reilly Edition, 2nd Ed., 2023
-
York, D. G., et al. (2000). The Sloan Digital Sky Survey: Technical Summary. AJ 120, 1579. arXiv:astro-ph/0006396
-
Binney, J. & Merrifield, M. (1998). Galactic Astronomy. Princeton University Press
-
Lupton, R., Gunn, J. E., & Szalay, A. (1999). A Modified Magnitude Scale that Behaves Well for Faint Objects. AJ 118, 1406. arXiv:astro-ph/9903081
-
Lupton, R., et al. (2004). Preparing Red-Green-Blue Images from CCD Data. PASP 116, 133. arXiv:astro-ph/0312483
-
Janesick, J. R. (2001). Scientific Charge-Coupled Devices. SPIE Press. (disponible en ligne)
-
Flamary, R., et al. (2022). Deep Learning for Galaxy Deconvolution. Frontiers in Astronomy and Space Sciences, 9, 1001043. doi:10.3389/fspas.2022.1001043 Click and Read
-
Asensio Ramos, A., et al. (2024). Solar multiobject multiframe blind deconvolution with a spatially variant convolution neural emulator. Astronomy & Astrophysics, 688, A81. arXiv:2407.05398
-
Kingma, D. P., & Welling, M. (2013). Auto-Encoding Variational Bayes. ICLR 2014. arXiv:1312.6114
-
Goodfellow, I., et al. (2014). Generative Adversarial Networks. NeurIPS 2014. arXiv:1406.2661
-
Ho, J., Jain, A., & Abbeel, P. (2020). Denoising Diffusion Probabilistic Models. NeurIPS 2020. arXiv:2006.11239
Enjoy Reading This Article?
Here are some more articles you might like to read next: