Architectures convolutives pour l'astronomie — DDPM 1
Série — Modèles génératifs appliqués aux images de galaxies Ce billet est le premier d’une série consacrée à l’application des modèles de diffusion (DDPM) aux images de galaxies du catalogue Galaxy Zoo 2. Je suis en train de le coder, je suis en train d’apprendre. Je prends des notes, j’essaie, je me plante, alors je partage. C’est pas un cours, c’est un billet de blog.
C’est axé sur le code DDPM que j’ai écrit et qui se trouve à cette adresse https://github.com/GregS1t/DDPM_GalaxyZoo2 Les dev. sont réalisés en PyTorch.
Pour ce premier billet, je vais aborder rapidement les briques fondamentales qui vont me permettre de construire un modèle de diffusion.
- Un peu de convolution
- Du ResNet
- Du U-Net
- Du conditionnement temporel
1. Pourquoi des convolutions ?
Je ne vais pas refaire toute la théorie sur la convolution. Je vous conseille la lecture du livre d’Aurélien Géron (voir la ref. à la fin). Quand on traite une image astro., le signal physique est local : le profil de brillance, le gradient de couleur, la texture d’une région sont des structures qui s’expriment sur quelques dizaines de pixels. Si j’utilisais un réseau entièrement connecté (fully connected network - aka FCN), il traiterait chaque pixel indépendamment, ignorant toute cohérence spatiale et nécessiterait un nombre de paramètres prohibitif. Ce n’est pas propre à l’astro d’ailleurs.
Une couche convolutive résout les deux problèmes à la fois. Elle applique un filtre $\mathbf{W} \in \mathbb{R}^{k \times k}$ qui se déplace sur l’image par translation (sliding window), extrayant des motifs locaux de manière “translationnellement invariante” (ça s’est dit) :
\[(\mathbf{x} \star \mathbf{W})[i,j] = \sum_{u=-\lfloor k/2 \rfloor}^{\lfloor k/2 \rfloor} \sum_{v=-\lfloor k/2 \rfloor}^{\lfloor k/2 \rfloor} \mathbf{x}[i+u,\, j+v]\; \mathbf{W}[u,v]\]En pratique, on empile $C_\text{out}$ filtres différents, produisant $C_\text{out}$ cartes de caractéristiques (feature maps). Le nombre de paramètres d’une telle couche est $C_\text{in} \times C_\text{out} \times k^2$, indépendant de la résolution spatiale de l’image — un avantage décisif.
2. Seulement voilà ! Le problème du gradient vanishing
Dès 2015, c’était bien sympa d’empiler une vingtaine de couches convolutives, ça pouvait encore fonctionner. Mais au-delà d’un certain nombre de couches, l’entraînement par rétropropagation se heurte à un obstacle fondamental : le gradient vanishing (disparition du gradient).
2.1 Intuition
Si j’ai un réseau à $L$ couches. je note $\mathbf{h}^{(k)} \in \mathbb{R}^{n_k}$ l’activation (vecteur de sortie) de la couche $k$, avec $\mathbf{h}^{(0)} = \mathbf{x}$ l’entrée du réseau et $\mathbf{h}^{(L)}$ sa sortie finale. $\mathbf{W}^{(\ell)}$ désigne l’ensemble des paramètres apprenables (poids et biais) de la couche $\ell$.
Lors de la rétropropagation, le gradient de la loss $\mathcal{L}$ par rapport aux paramètres d’une couche profonde $\ell$ s’écrit comme un produit de Jacobiens :
\[\frac{\partial \mathcal{L}}{\partial \mathbf{W}^{(\ell)}} = \frac{\partial \mathcal{L}}{\partial \mathbf{h}^{(L)}} \cdot \prod_{k=\ell}^{L-1} \frac{\partial \mathbf{h}^{(k+1)}}{\partial \mathbf{h}^{(k)}} \cdot \frac{\partial \mathbf{h}^{(\ell)}}{\partial \mathbf{W}^{(\ell)}}\]Si chaque facteur du produit a une norme spectrale* inférieure à 1 (ce qui est fréquent avec une activation $\texttt{sigmoid}$ ou $\texttt{tanh}$), le produit décroît exponentiellement avec la profondeur $L - \ell$. Les couches proches de l’entrée reçoivent un gradient quasi nul et n’apprennent plus rien.
2.2 Premières solutions partielles
Plusieurs palliatifs ont été proposés avant ResNet :
- ReLU : élimine la saturation des activations, mais n’élimine pas le problème.
- Batch Normalization (Ioffe & Szegedy, 2015) : normalise les activation intermédiaires, stabilise les gradients, permet d’utiliser des $\textit{learning rates}$ plus élevés.
- Initialisation soignée (Glorot, He) : calibre la variance des poids à l’initialisation pour maintenir la norme du gradient.
Ces techniques améliorent la situation mais ne la résolvent pas structurellement.
3. Les connexions résiduelles — ResNet
He et al. (2015) proposent une solution élégante : au lieu d’apprendre une transformation $\mathcal{F}(\mathbf{x})$, on apprend la résiduelle
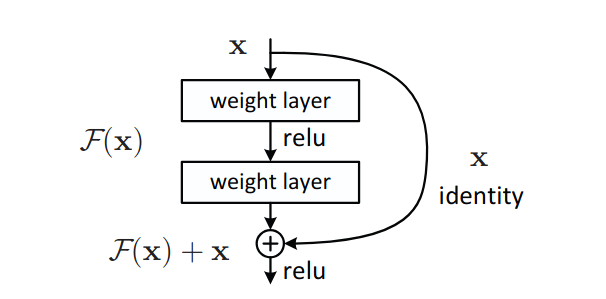
$\mathcal{F}(\mathbf{x}) = \mathcal{H}(\mathbf{x}) - \mathbf{x}$, où $\mathcal{H}(\mathbf{x})$ est la transformation souhaitée. La sortie du bloc devient alors :
\[\boxed{\mathbf{y} = \mathcal{F}(\mathbf{x},\, \{\mathbf{W}_i\}) + \mathbf{x}}\]Le terme $+ \mathbf{x}$ est la connexion résiduelle (skip connection). Elle court-circuite les couches intermédiaires en additionnant directement l’entrée à la sortie du bloc.
3.1 Pourquoi ça résout le gradient vanishing ?
Le gradient de la loss par rapport à l’entrée $\mathbf{x}$ du bloc vaut :
\[\frac{\partial \mathcal{L}}{\partial \mathbf{x}} = \frac{\partial \mathcal{L}}{\partial \mathbf{y}} \cdot \frac{\partial \mathbf{y}}{\partial \mathbf{x}} = \frac{\partial \mathcal{L}}{\partial \mathbf{y}} \cdot \left(1 + \frac{\partial \mathcal{F}}{\partial \mathbf{x}}\right)\]Le terme $1$ garantit qu’il existe toujours un chemin de gradient direct depuis la sortie vers l’entrée, quelle que soit la profondeur du réseau. Même si $\partial \mathcal{F}/\partial \mathbf{x}$ devient petit, le gradient ne disparaît pas.
Intuitivement : si le bloc résiduel n’apprend rien ($\mathcal{F}(\mathbf{x}) \to 0$), il se comporte comme une identité — la couche est neutralisée sans perturber le reste du réseau. Cela rend l’optimisation plus robuste et permet d’entraîner des réseaux de plusieurs centaines de couches.
3.2 Le ResBlock dans notre code
Dans notre implémentation (ddpm_unet.py), le bloc de base s’appelle ConvResBlock. Il est intentionnellement simplifié par rapport au ResBlock original de He et al. : il ne contient pas de connexion résiduelle additive explicite $+ \mathbf{x}$, mais hérite de la philosophie ResNet via l’empilement modulaire et la normalisation. Son rôle est de constituer une brique composable pour l’encodeur et le décodeur du U-Net.
class ConvResBlock(nn.Module):
"""
Bloc convolutif à deux couches avec LayerNorm optionnelle.
Pipeline : [LayerNorm] -> Conv2d -> SiLU -> Conv2d -> SiLU
Un canal intermédiaire (mid_channels) permet un effet de bottleneck.
"""
def __init__(self, input_shape, in_channels, out_channels,
activation=None, normalize=False, mid_channels=None):
super().__init__()
self.normalize = normalize
self.norm = nn.LayerNorm(input_shape)
self.activation = nn.SiLU() if activation is None else activation
mid = mid_channels if mid_channels is not None else out_channels
self.conv1 = nn.Conv2d(in_channels, mid, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(mid, out_channels, kernel_size=3, padding=1)
def forward(self, x):
out = self.norm(x) if self.normalize else x
out = self.activation(self.conv1(out))
out = self.activation(self.conv2(out))
return out
Pourquoi SiLU plutôt que ReLU ? La SiLU (Sigmoid Linear Unit, $f(x) = x \cdot \sigma(x)$) correspond à la fonction Swish de Ramachandran et al. (2017) avec le paramètre $\beta = 1$ fixé. Contrairement à la ReLU qui annule strictement les valeurs négatives, la SiLU est partout dérivable et laisse passer une fraction des activations négatives, produisant des gradients plus réguliers. C’est un choix d’implémentation de notre part : la SiLU est couramment adoptée dans les réimplémentations de DDPM pour sa régularité numérique, mais Ho et al. (2020) n’en font pas mention explicitement dans leur papier original.
Pourquoi LayerNorm et non BatchNorm ? La BatchNorm normalise sur le mini-batch entier, ce qui introduit une dépendance entre les exemples. Dans les modèles de diffusion, chaque image est conditionnée par son propre pas de temps $t$ — la statistique de batch devient hétérogène. La LayerNorm normalise indépendamment par exemple (sur les axes $C, H, W$), ce qui est plus stable dans ce contexte.
4. Le U-Net
Le U-Net (Ronneberger et al., 2015) a été conçu à l’origine pour la segmentation d’images biomédicales. Son architecture en forme de “U” lui a valu son nom : un encodeur qui compresse l’information spatiale, un bottleneck (goulot d’étranglement), et un décodeur qui la reconstruit — le tout relié par des skip connections entre niveaux symétriques. Passons en revue les trois blocs…
4.1 L’encodeur — extraire et compresser
L’encodeur est une suite de blocs convolutifs séparés par des opérations de sous-échantillonnage (downsampling). À chaque niveau, la résolution spatiale est divisée par 2 tandis que le nombre de canaux augmente, forçant le réseau à construire des représentations de plus en plus abstraites.
Dans l’U-Net original (Ronneberger et al., 2015), le sous-échantillonnage est réalisé par un max-pooling 2×2 stride-2. Dans notre implémentation, nous le remplaçons par une convolution stride-2 (paramètres apprenables), suivant Springenberg et al. (2014). Cela permet au réseau d’apprendre lui-même comment réduire la résolution, plutôt que d’appliquer une opération de sélection fixe.
Entrée (N, 3, 64, 64)
enc1 -> (N, 16, 64, 64) — 3 × ConvResBlock
down1 -> (N, 16, 32, 32) — Conv2d stride=2
enc2 -> (N, 32, 32, 32) — 3 × ConvResBlock
down2 -> (N, 32, 16, 16) — Conv2d stride=2
enc3 -> (N, 64, 16, 16) — 3 × ConvResBlock
down3 -> (N, 64, 8, 8) — Conv2d stride=2
4.2 Le bottleneck — représentation latente
Le bottleneck est le niveau de résolution minimale (8×8 dans notre cas). C’est là que le réseau dispose de la vision la plus globale de l’image. Dans un modèle de diffusion, c’est à ce niveau que l’information sur le pas de temps $t$ a le plus d’influence sur la dynamique de débruitage.
# Bottleneck : (N, 64, 8, 8) -> (N, 64, 8, 8)
self.bottleneck = nn.Sequential(
ConvResBlock((64, 8, 8), 64, 128, mid_channels=256),
ConvResBlock((128, 8, 8), 128, 128),
ConvResBlock((128, 8, 8), 128, 64),
)
L’expansion intermédiaire jusqu’à 256 canaux (mid_channels=256) crée un effet de bottleneck inversé : le réseau dispose d’une plus grande capacité représentationnelle au centre du U, là où l’information sémantique est la plus concentrée.
4.3 Le décodeur et les skip connections
Le décodeur reconstruit progressivement la résolution spatiale par des convolutions transposées (upsampling). La nouveauté clé du U-Net est que chaque niveau du décodeur reçoit en entrée deux flux concatenés :
- La sortie du niveau précédent du décodeur (information sémantique globale)
- La sortie du niveau symétrique de l’encodeur (information locale fine)
où $[\cdot | \cdot]$ désigne la concaténation selon l’axe des canaux.
# Skip connection au niveau 1 du décodeur
feat_dec1 = torch.cat([feat_enc3, self.up1(feat_mid)], dim=1) # (N, 128, 16, 16)
feat_dec1 = self.dec1(feat_dec1 + time_cond(self.time_proj_dec1, t_emb))
# Skip connection au niveau 2
feat_dec2 = torch.cat([feat_enc2, self.up2(feat_dec1)], dim=1) # (N, 64, 32, 32)
feat_dec2 = self.dec2(feat_dec2 + time_cond(self.time_proj_dec2, t_emb))
# Skip connection au niveau 3 — retour à la résolution d'entrée
feat_dec3 = torch.cat([feat_enc1, self.up3(feat_dec2)], dim=1) # (N, 32, 64, 64)
feat_dec3 = self.dec3(feat_dec3 + time_cond(self.time_proj_dec3, t_emb))
Pourquoi les skip connections sont essentielles ici ? Dans notre contexte de prédiction de bruit, le réseau doit produire une image de même résolution que l’entrée. Sans les skip connections, l’encodeur compresserait l’information spatiale de manière irréversible. Grâce à elles, les détails fin-grain (localisation précise des structures galactiques, gradients de brillance) sont directement accessibles au décodeur, contournant le goulot d’étranglement.
4.4 Vue d’ensemble de l’architecture
Le tableau ci-dessous récapitule les dimensions des feature maps à chaque étape. Les flèches ← indiquent les skip connections : la feature map de l’encodeur est concaténée avec la sortie de l’upsampling avant le bloc convolutif du décodeur.
| Étape | Bloc | Entrée | Sortie |
|---|---|---|---|
| Encodeur | |||
| enc1 | 3× ConvResBlock | (N, 3, 64, 64) | (N, 16, 64, 64) |
| down1 | Conv2d stride=2 | (N, 16, 64, 64) | (N, 16, 32, 32) |
| enc2 | 3× ConvResBlock | (N, 16, 32, 32) | (N, 32, 32, 32) |
| down2 | Conv2d stride=2 | (N, 32, 32, 32) | (N, 32, 16, 16) |
| enc3 | 3× ConvResBlock | (N, 32, 16, 16) | (N, 64, 16, 16) |
| down3 | Conv2d stride=2 | (N, 64, 16, 16) | (N, 64, 8, 8) |
| Bottleneck | |||
| bottleneck | 3× ConvResBlock | (N, 64, 8, 8) | (N, 64, 8, 8) |
| Décodeur | |||
| up1 + ← enc3 | ConvTranspose2d + cat | (N, 64, 8, 8) | (N, 128, 16, 16) |
| dec1 | 3× ConvResBlock | (N, 128, 16, 16) | (N, 32, 16, 16) |
| up2 + ← enc2 | ConvTranspose2d + cat | (N, 32, 16, 16) | (N, 64, 32, 32) |
| dec2 | 3× ConvResBlock | (N, 64, 32, 32) | (N, 16, 32, 32) |
| up3 + ← enc1 | ConvTranspose2d + cat | (N, 16, 32, 32) | (N, 32, 64, 64) |
| dec3 | 3× ConvResBlock | (N, 32, 64, 64) | (N, 16, 64, 64) |
| Sortie | |||
| conv_out | Conv2d 3×3 | (N, 16, 64, 64) | (N, 3, 64, 64) |
La sortie est une image de même taille que l’entrée : c’est exactement ce qu’il faut pour prédire le bruit $\boldsymbol{\varepsilon}_\theta(\mathbf{x}_t, t)$ dans le DDPM — un champ vectoriel de même dimension que l’image bruitée.
5. Conditionnement temporel
Le U-Net décrit ci-dessus est un réseau image-vers-image. Pour l’utiliser dans un DDPM, il faut lui communiquer le pas de temps $t$ courant, qui détermine le niveau de bruit de l’image en entrée et donc le type de débruitage attendu.
Cette injection est réalisée par des embeddings sinusoïdaux projetés par un MLP à chaque niveau de l’architecture. Ce mécanisme fait l’objet d’un billet dédié →.
Schématiquement, à chaque niveau $\ell$ :
\[\mathbf{f}_\text{enc}^{(\ell)} = \text{ConvBlock}\!\left( \mathbf{f}^{(\ell-1)} + \text{MLP}_\ell\!\left(\mathbf{e}(t)\right) \right)\]où $\mathbf{e}(t) \in \mathbb{R}^d$ est l’embedding sinusoïdal de $t$ et $\text{MLP}_\ell$ projette cet embedding vers la dimension des canaux du niveau $\ell$.
6. Résumé
Liste des concepts rencontrés
| Concept | Rôle dans notre architecture | |—|—| | Convolution | Extraction de motifs locaux translationnellement invariants | | ResBlock | Brique convolutive composable, stable à la profondeur | | SiLU | Activation continue, gradients doux pour la diffusion | | LayerNorm | Normalisation par exemple, robuste au conditionnement par $t$ | | Encodeur | Compression progressive : résolution ↓, abstraction ↑ | | Bottleneck | Représentation globale à résolution minimale (8×8) | | Décodeur | Reconstruction spatiale progressive | | Skip connections | Transfert direct de l’information fine encodeur → décodeur | | Conditionnement $t$ | Injection du pas de temps par embedding sinusoïdal + MLP |
L’architecture complète (UNetGZ2) compte environ 12 M paramètres entraînables pour des images 64×64×3. Le code source complet est disponible dans le dépôt du projet : ddpm_unet.py.
Principales fonctions PyTorch utilisées
| Fonction | Rôle dans l’architecture | |
|---|---|---|
nn.Conv2d | Convolution 2D — extraction de features, downsampling (stride=2) | |
nn.ConvTranspose2d | Convolution transposée — upsampling dans le décodeur | |
nn.LayerNorm | Normalisation par exemple sur les axes (C, H, W) | |
nn.SiLU | Activation Sigmoid Linear Unit — $f(x) = x \cdot \sigma(x)$ | |
nn.Embedding | Table de correspondance $t \to \mathbf{e}(t)$ pour les embeddings temporels | |
nn.Linear | Couche linéaire — projection des embeddings temporels par le MLP | |
nn.Sequential | Enchaînement de modules en pipeline | |
torch.cat | Concaténation des skip connections le long de l’axe des canaux |
Références
-
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep Residual Learning for Image Recognition. CVPR 2016. arXiv:1512.03385
-
Ronneberger, O., Fischer, P., & Brox, T. (2015). U-Net: Convolutional Networks for Biomedical Image Segmentation. MICCAI 2015. arXiv:1505.04597
-
Ioffe, S., & Szegedy, C. (2015). Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. ICML 2015. arXiv:1502.03167
-
Ho, J., Jain, A., & Abbeel, P. (2020). Denoising Diffusion Probabilistic Models. NeurIPS 2020. arXiv:2006.11239
-
Ramachandran, P., Zoph, B., & Le, Q. V. (2017). Searching for Activation Functions. arXiv:1710.05941
-
Springenberg, J. T., Dosovitskiy, A., Brox, T., & Riedmiller, M. (2014). Striving for Simplicity: The All Convolutional Net. arXiv:1412.6806
-
Géron A. Deep Learning avec Keras et Tensorflow, Dunod Edition, 2ème édition, 2020.
Prochain billet : Les embeddings sinusoïdaux — conditionner un réseau sur le temps →
Enjoy Reading This Article?
Here are some more articles you might like to read next: