Les embeddings sinusoïdaux, conditionner un réseau sur le temps - DDPM 2
Série — Modèles génératifs appliqués aux images de galaxies Ce billet est le deuxième d’une série consacrée à l’application des modèles de diffusion (DDPM) aux images de galaxies du catalogue Galaxy Zoo 2. Le code complet est disponible sur github.com/GregS1t/DDPM_GalaxyZoo2.
1. Le problème : comment dire l’heure au réseau ?
Dans un DDPM, le réseau de débruitage $\boldsymbol{\varepsilon}_\theta(\mathbf{x}_t, t)$ doit traiter différemment une image très bruitée (grand $t$) et une image quasi-propre (petit $t$). Il a donc besoin de savoir à quel pas de temps $t$ il opère.
La solution naïve serait de passer $t$ comme un scalaire supplémentaire. Mais un scalaire est une information très pauvre — le réseau aurait du mal à l’exploiter directement dans ses couches convolutives, qui travaillent sur des tenseurs $(N, C, H, W)$.
L’idée, empruntée aux Transformers (Vaswani et al., 2017), est de projeter $t$ dans un espace de haute dimension via des fonctions sinusoïdales. On obtient un vecteur $\mathbf{e}(t) \in \mathbb{R}^d$ qui peut ensuite être injecté dans chaque niveau du U-Net par une simple addition.
2. La formule
Pour un pas de temps $t \in {0, \dots, T-1}$ et une dimension d’embedding $d$ (paire), on définit :
\[\mathbf{e}(t)_{2i} = \sin\!\left(\frac{t}{10000^{2i/d}}\right) \qquad \mathbf{e}(t)_{2i+1} = \cos\!\left(\frac{t}{10000^{2i/d}}\right)\]pour $i = 0, 1, \dots, d/2 - 1$.
Chaque paire $(2i, 2i+1)$ correspond à une fréquence différente :
\[\omega_i = \frac{1}{10000^{2i/d}}\]- Pour $i = 0$ : $\omega_0 = 1$ — période de $2\pi \approx 6$ pas de temps. Le réseau voit les variations rapides.
- Pour $i = d/2 - 1$ : $\omega_{d/2-1} = 10000^{-1}$ — période de $2\pi \times 10000 \approx 62\,800$ pas. Le réseau voit les tendances lentes.
L’ensemble des fréquences couvre plusieurs décades, donnant au réseau une représentation multi-échelle du temps — un peu comme une décomposition de Fourier du signal temporel.
3. Propriétés clés
Déterministe et sans paramètres. La table est calculée une seule fois à l’initialisation et ses poids sont gelés (requires_grad_(False)). Aucun paramètre supplémentaire, aucun risque de surapprentissage sur le temps.
Unique par pas de temps. Deux pas de temps différents produisent des vecteurs différents. C’est une condition nécessaire pour que le réseau puisse distinguer les niveaux de bruit.
Lisse. Les fonctions sinus et cosinus sont continues : deux pas de temps proches $t$ et $t+1$ donnent des embeddings proches. Cela aide l’optimiseur à interpoler correctement entre les pas de temps.
Extensible. L’embedding est défini pour tout entier $t$, même au-delà de $T$. On peut donc utiliser le modèle avec un nombre de pas différent de celui de l’entraînement (utile pour l’inférence accélérée).
4. Implémentation dans notre code
def sinusoidal_embedding(n_steps, embed_dim):
"""Sinusoidal positional embeddings — Vaswani et al. (2017), Eq. 1-2."""
assert embed_dim % 2 == 0
embedding = torch.zeros(n_steps, embed_dim)
positions = torch.arange(n_steps, dtype=torch.float32) # (T,)
half_dim = embed_dim // 2
# Fréquences : 10000^(2i/d) pour i dans [0, d/2)
freq = 10000.0 ** (torch.arange(half_dim, dtype=torch.float32) / embed_dim)
embedding[:, 0::2] = torch.sin(positions[:, None] / freq[None, :])
embedding[:, 1::2] = torch.cos(positions[:, None] / freq[None, :])
return embedding
Cette table est ensuite chargée dans un nn.Embedding dont les poids sont gelés :
self.time_embedding = nn.Embedding(n_steps, time_embed_dim)
self.time_embedding.weight.data = sinusoidal_embedding(n_steps, time_embed_dim)
self.time_embedding.requires_grad_(False)
À chaque forward pass, le pas de temps $t$ (un tenseur d’entiers de taille $(N,)$) est converti en vecteurs d’embedding $(N, d)$ par un simple lookup :
t_emb = self.time_embedding(t) # (N, time_embed_dim)
Ces vecteurs sont ensuite projetés vers la dimension des canaux de chaque niveau du U-Net par un petit MLP, puis broadcast-additionnés aux feature maps (voir billet 1).
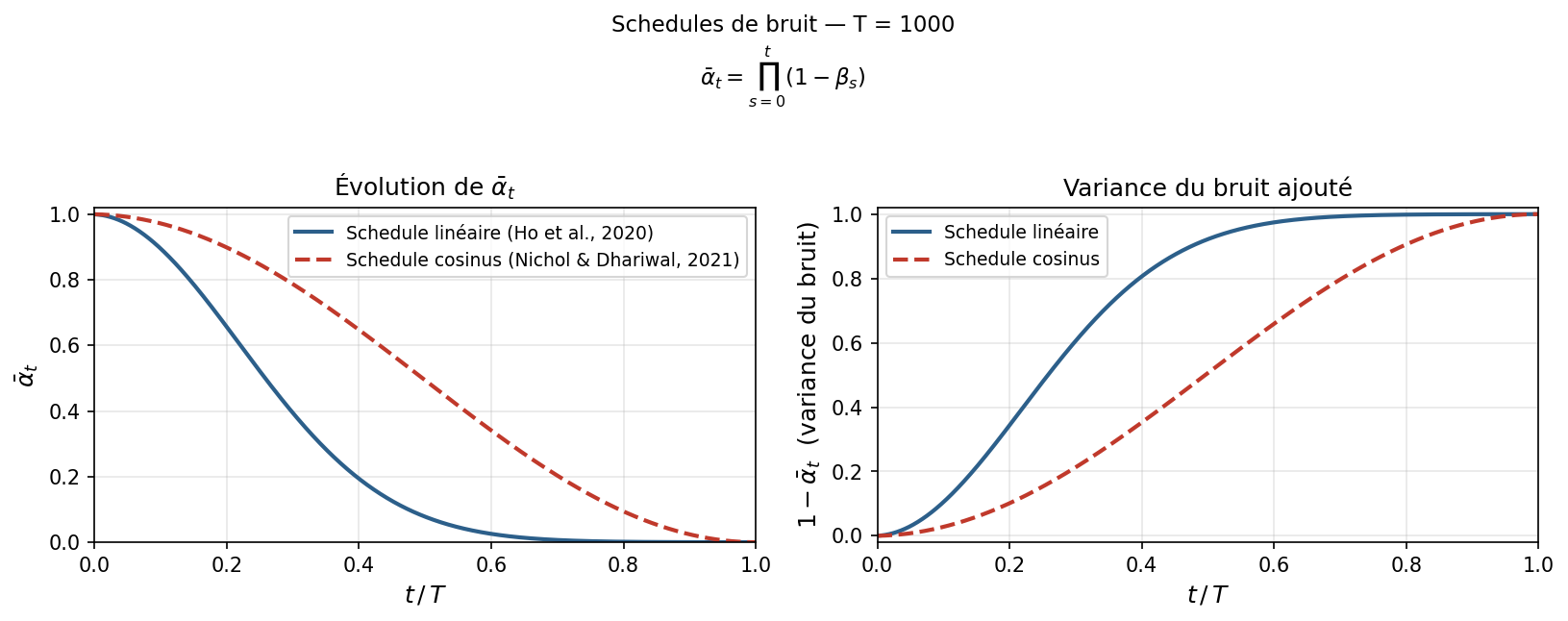
5. Schedule linéaire vs schedule cosinus
Les embeddings sinusoïdaux encodent le numéro du pas de temps $t$. Ce que le réseau apprend à débruiter dépend aussi du niveau de bruit effectif à ce pas de temps, contrôlé par le schedule de bruit $\bar{\alpha}_t$.
Schedule linéaire (Ho et al., 2020)
Ho et al. (2020) définissent un schedule linéaire sur les $\beta_t$ :
\[\beta_t = \beta_\text{start} + \frac{t}{T-1}(\beta_\text{end} - \beta_\text{start}) \qquad \bar{\alpha}_t = \prod_{s=0}^{t}(1 - \beta_s)\]avec $\beta_\text{start} = 10^{-4}$ et $\beta_\text{end} = 0.02$.
Schedule cosinus (Nichol & Dhariwal, 2021)
Nichol & Dhariwal (2021) proposent de définir $\bar{\alpha}_t$ directement par une fonction cosinus, de façon à obtenir une décroissance plus régulière :
\[\bar{\alpha}_t = \frac{f(t)}{f(0)}, \qquad f(t) = \cos^2\!\left(\frac{t/T + s}{1 + s} \cdot \frac{\pi}{2}\right)\]avec un petit décalage $s = 0.008$ pour éviter que $\bar{\alpha}_t$ soit trop proche de 1 en début de processus.
Comparaison
Avec le schedule linéaire, $\bar{\alpha}_t$ décroît rapidement : l’image devient quasi-pure noise dès $t \approx T/2$, ce qui est sous-optimal pour l’entraînement (la moitié des pas de temps ne contient plus d’information sur $\mathbf{x}_0$). Le schedule cosinus maintient un signal utile plus longtemps et assure une transition plus douce vers le bruit pur.
Note : dans notre implémentation actuelle, nous utilisons le schedule linéaire de Ho et al. (2020), cohérent avec le code de référence. Les figures ci-dessous illustrent la différence entre les deux pour $T = 1000$ — une piste d’amélioration future.
6. Visualisation des embeddings
La figure ci-dessous représente la table d’embedding complète pour $T = 1000$ pas de temps et $d = 100$ dimensions. Chaque ligne correspond à un vecteur $\mathbf{e}(t)$, chaque colonne à une composante.

Références
-
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention is All You Need. NeurIPS 2017. arXiv:1706.03762
-
Ho, J., Jain, A., & Abbeel, P. (2020). Denoising Diffusion Probabilistic Models. NeurIPS 2020. arXiv:2006.11239
-
Nichol, A., & Dhariwal, P. (2021). Improved Denoising Diffusion Probabilistic Models. ICML 2021. arXiv:2102.09672
Prochain billet : Formalisme DDPM complet →
Enjoy Reading This Article?
Here are some more articles you might like to read next: