Clustering multi-échelle et séparation de sources sur les données InSight
Petit billet de blog sur un article paru début 2026 intitulé Multiscale Clustering and Source Separation of InSight Mission Seismic Data dans IEEE Transactions on Geoscience and Remote Sensing, et dont je suis co-auteur.
Le problème : un cocktail de signaux à toutes les échelles
Commençons par une petite métaphore : vous avez un micro, un casque sur les oreilles et vous enregistrez l’ambiance sonore d’une ville depuis un même point fixe : le souffle du vent, les vibrations du trafic routier, les bruits de pas des passants, peut-être des coups de tonnerre lointains… Toutes ces sources se superposent, et vous n’avez aucune “étiquette” pour les distinguer. À la fin, vous n’avez qu’un seul signal qui contient tout cela. Comment séparer chaque composante ? Les scientifiques qui ont analysés les données du sismomètre SEIS de la mission InSight sur Mars ont fait face au même défi.
Le signal est un mélange “hétérogène” (pour rester poli) de :
- Glitches : impulsions transitoires de quelques dizaines de secondes, probablement dues à des craquements thermiques de l’instrument, du tether…
- Dust devils : tourbillons de poussière.
- Bruits de vent : rafales à haute fréquence et oscillations soutenues, corrélées au cycle jour/nuit martien.
- Interactions atmosphère-surface : phénomènes à l’échelle de la dizaine ou la cinquantaine de minutes (lever de soleil, variations de température régionale…).
- Marsquakes : rares (39 événements sur 4 ans) mais scientifiquement précieux pour déterminer la structure interne de la planète rouge.
Dans l’analyse de ces signaux, la difficulté centrale est la diversité des échelles de temps. Les méthodes classiques ne peuvent opérer qu’à une seule échelle à la fois.
Cet article a justement proposé une solution entièrement non supervisée qui couvre toutes ces échelles simultanément.
On va essayer de démêler l’architecture utilisée en la décomposant en éléments élémentaires.
Étage 1 — Pyramidal scattering spectra
Qu’est-ce que c’est ?
Avant de chercher à séparer des sources, il faut se donner une représentation du signal qui soit à la fois :
- compacte : pas question de travailler directement sur des millions d’échantillons bruts,
- discriminante : deux types de sources différents doivent avoir des représentations différentes,
- sensible aux structures non-gaussiennes : les glitches, les rafales de vent, les dust devils ne sont pas du bruit gaussien, ils ont des formes caractéristiques que la variance seule ne capture pas.
Un spectre de puissance classique (FFT) échoue sur ce dernier point : deux signaux très différents peuvent avoir le même spectre de puissance. C’est ici qu’interviennent les réseaux de scattering par ondelettes (Bruna & Mallat, 2013).
Un tel réseau est un CNN à filtres prédéfinis (par des ondelettes) organisé en deux couches :
- Couche 1 : la transformée en ondelettes du signal, $Wx$, qui extrait les variations de $x$ à chaque échelle $2^j$ — analogue à un spectrogramme multi-résolution.
- Couche 2 : la transformée en ondelettes appliquée aux enveloppes de la couche 1, $W\vert Wx \vert$, qui capture comment les échelles interagissent entre elles, ce qu’on ne voit pas avec une FFT.
Le spectre de scattering $\Psi(x)$ est alors la matrice de covariance diagonale de $S(x) = (Wx, W \vert Wx \vert)^\top$ : il résume en un vecteur de faible dimension les propriétés statistiques non-gaussiennes du signal (intermittence, asymétrie temporelle, modulation d’enveloppe).
Pourquoi l’extension pyramidale ?
Le spectre de scattering $\Psi(x)$ qu’on a défini au dessus calcule une moyenne sur une seule fenêtre temporelle. C’est là que le problème se pose : si la fenêtre est trop grande, un glitch de 50 s est perdu dans la moyenne et disparaît de la représentation. Si elle est trop petite, une interaction atmosphérique de 54 min n’est pas capturée du tout.
Je ne crois pas qu’il existe pas de “bonne” fenêtre unique : les sources ont des durées propres, qui s’étalent sur trois ordres de grandeur.
La solution serait donc de calculer K spectres en parallèle, chacun avec une fenêtre de taille différente, toutes ancrées au même instant (pyramide causale) :
\[\Psi_k(x) = \operatorname{Ave}_{t \in w_k}\!\left[ S(x),\; \operatorname{diag}\bigl(S(x)\,S(x)^\top\bigr) \right]\]avec $w_{k+1}$ quatre fois plus long que $w_k$. Dans l’article, quatre échelles sont utilisées : 51,2 s, 3,4 min, 13,6 min et 54,6 min.
L’idée clé : une source n’est visible dans $\Psi_k(x)$ que si sa durée est comparable à $w_k$. En empilant quatre fenêtres, on garantit qu’aucune source ne sera invisibilisée par un mauvais choix d’échelle et chaque $\Psi_k$ alimentera son propre espace de clustering dans l’étage suivant.
Analogie : c’est comme observer une forêt avec un drone à quatre altitudes différentes : de près, on distingue les branches individuelles (glitches) ; de loin, on ne voit que la canopée globale (tendances atmosphériques de fond).
Étage 2 — Le VAE factoriel (fVAE)
Pourquoi un Gaussian-mixture VAE ?
On dispose maintenant de quatre représentations $\Psi_1(x), \ldots, \Psi_4(x)$ pour chaque fenêtre du signal. L’étape suivante est de regrouper automatiquement les fenêtres qui se ressemblent, c’est-à-dire de faire du clustering … sans aucune étiquette. On appelle ça de l’apprentissage non supervisé.
Mais on veut plus que juste des clusters : on veut aussi pouvoir générer des exemples synthétiques de chaque type de source. Pourquoi ? Parce que ces exemples serviront de prior dans l’étape de séparation (étage 3) : pour extraire un glitch d’un signal mélangé… il faut savoir à quoi ressemble statistiquement un glitch.
Un Gaussian-mixture VAE répond aux deux besoins simultanément :
- le Gaussian mixture dans l’espace latent crée des clusters distincts,
- le décodeur permet de générer de nouveaux échantillons depuis n’importe quel cluster.
Pourquoi une structure factorielle ?
Un VAE classique apprendrait une représentation latente unique pour l’ensemble du signal. Ce n’est pas ce qu’on veut : un glitch et une interaction atmosphérique coexistent dans la même fenêtre de 54,6 min, mais ils n’opèrent pas à la même échelle.
La structure factorielle du fVAE résout ce problème en dédiant un espace latent par échelle de temps :
\[p_\theta(u, y, z) = \prod_{i=0}^{s-1} p_\theta(u_i | z_i)\; p_\theta(z_i | y_i)\; p_\theta(y_i)\]où $u_i = \Psi_i(x)$ est la représentation scattering à l’échelle $i$, $y_i$ est la variable de cluster (catégorielle), et $z_i$ suit un Gaussian mixture conditionnel.
Concrètement : le fVAE a un encodeur partagé (qui voit toutes les échelles à la fois) suivi de quatre paires encodeur/décodeur indépendantes, une par échelle. Les décodeurs étant indépendants, on peut échantillonner la distribution d’une source à l’échelle 1 (glitch) sans interférer avec ce qu’on observe à l’échelle 4 (vent soutenu).
L’entraînement maximise l’ELBO, la borne inférieure de la vraisemblance des données — sur l’intégralité des données InSight (environ 51 h sur une Tesla V100, 9 composantes de Gaussian mixture par échelle, dimension latente 32).
Étage 3 — Séparation de sources non supervisée
Comment séparer une source d’un mélange ?
On dispose maintenant de clusters bien identifiés à chaque échelle, et on sait générer des exemples synthétiques de chaque type de source. C’est exactement ce dont on a besoin pour formuler la séparation comme un problème d’optimisation.
L’idée est la suivante : étant donnée une fenêtre observée $x = s_1 + n$ (une source d’intérêt $s_1$ noyée dans un résidu $n$), on cherche $\tilde{s}_1$ tel que :
- $\tilde{s}_1$ ressemble statistiquement aux échantillons du cluster correspondant,
- $x - \tilde{s}_1$ ressemble statistiquement au bruit de fond,
- $\tilde{s}_1$ et $x - \tilde{s}_1$ sont statistiquement indépendants.
Ces trois contraintes se traduisent en trois termes de loss, tous définis dans l’espace des spectres de scattering :
| Terme | Rôle |
|---|---|
| $\mathcal{L}_\text{prior}$ | $\tilde{s}_1$ a les mêmes statistiques que les échantillons du cluster |
| $\mathcal{L}_\text{data}$ | $x - \tilde{s}_1$ a les mêmes statistiques que le bruit de fond |
| $\mathcal{L}_\text{cross}$ | $\tilde{s}_1$ et $x - \tilde{s}_1$ sont statistiquement indépendants |
Pourquoi optimiser dans l’espace de scattering plutôt que directement dans le domaine temporel ? Parce que c’est là que les sources sont discriminables : deux types de sources peuvent se ressembler dans le domaine temporel tout en ayant des spectres de scattering très différents.
Chaque terme est normalisé par la variance empirique des coefficients de scattering, ce qui évite d’avoir à régler des poids relatifs à la main. L’optimisation est résolue par L-BFGS (1000 itérations, parallélisé sur 4 GPU).
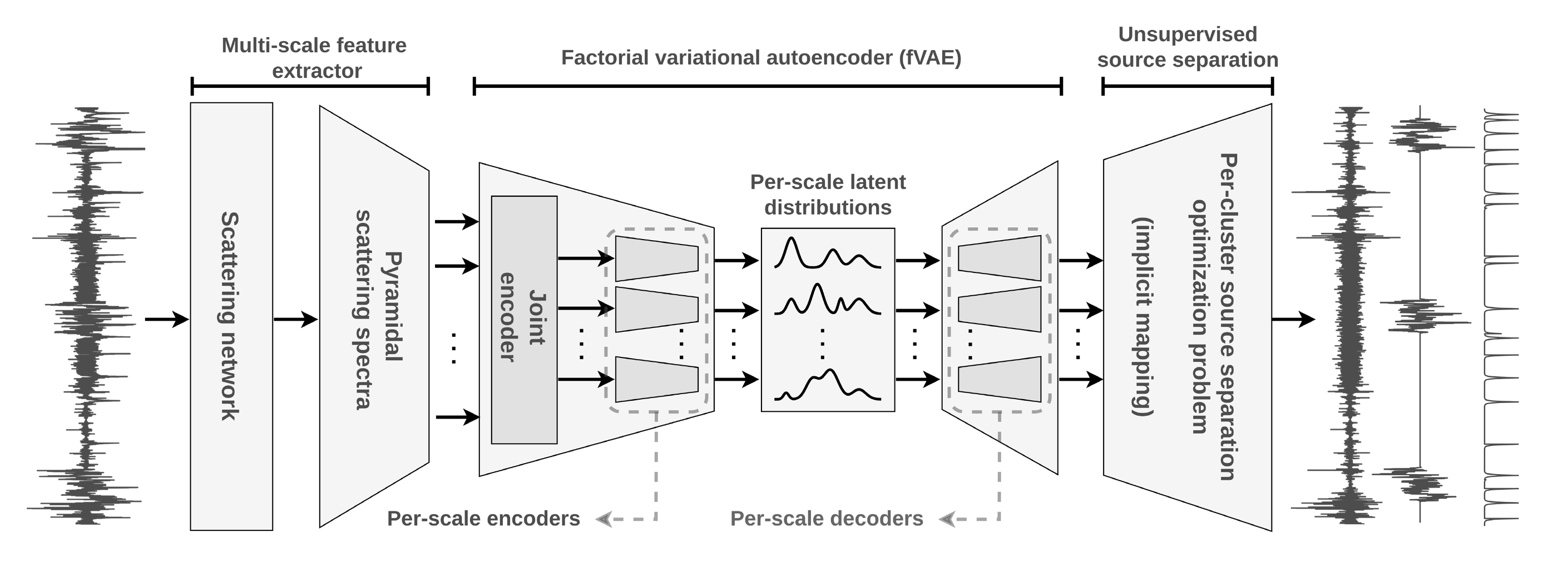
Résultats : Qui y’a t-il dans les données ?
Clustering multi-échelle
À chaque échelle de temps, le fVAE identifie 9 clusters. Pour les interpréter, on visualise deux choses : les formes d’onde alignées (les signaux typiques du cluster) et les histogrammes d’occurrence sur une journée martienne (à quelle heure du jour ces signaux apparaissent-ils le plus souvent ?). Cette dernière information est particulièrement utile : on sait par exemple que les dust devils sont majoritairement diurnes, ou que le bruit ambiant est plus faible la nuit.
Échelle fine (51,2 s) $\rightarrow$ on s’attend à voir des signaux transitoires courts :
- Cluster de glitches sans précurseur — fréquents autour du coucher de soleil martien.
- Cluster de glitches avec précurseur (spike d’amplitude juste avant l’impulsion) — même tendance temporelle.
Échelle intermédiaire (3,4 min) $\rightarrow$ les clusters reflètent des phénomènes plus longs :
- Cluster de signaux oscillatoires à ~25 s de période, corrélés au vent, surtout la nuit. L’origine de ces oscillations n’est pas encore identifiée, mais une cause instrumentale a été écartée.
- Cluster de rafales haute fréquence à dissipation rapide.
Échelle large (13,6 min) $\rightarrow$ les interactions atmosphère-surface émergent :
- Cluster de rafales de vent intenses : onset brutal suivi de ringing. L’histogramme montre une occurrence concentrée avant et après le coucher de soleil.
- Cluster de dust devils : cohérent avec la fenêtre 09h–15h LMST rapportée par les capteurs de pression InSight.
Échelle très large (54,6 min) $\rightarrow$ les phénomènes globaux dominent :
- Cluster de vents soutenus, similaire aux rafales de l’échelle précédente mais plus persistants.
- Cluster lié au lever de soleil : amplitude croissante, pic centré sur le début de journée martienne.
L’analyse saisonnière confirme la cohérence physique du clustering : les pics des histogrammes se décalent avec les horaires de lever/coucher de soleil saison après saison.
Séparation des sources
Le clustering ne sert pas qu’à décrire les données, il fournit les échantillons de prior nécessaires à la séparation. Deux expériences l’illustrent :
-
Extraction de glitches depuis une fenêtre nocturne de 54,6 min : les impulsions unilatérales sont supprimées avec un impact minimal sur le reste du signal. Sur une portion sans glitch, la méthode ne retire rien, c’est une propriété cruciale qui valide la robustesse de l’approche.
-
Extraction de l’empreinte du vent depuis une fenêtre diurne : les onsets brutaux suivis de ringing sont isolés proprement, laissant un résidu nettement plus calme.
Espace latent
La visualisation UMAP (réduction à 2D de l’espace latent de dimension 32) révèle une propriété remarquable : des signaux que le modèle n’a jamais vus comme classe à part entière se retrouvent spontanément regroupés au bon endroit.
- Les marsquakes (39 événements sur 4 ans, jamais assez nombreux pour former leur propre cluster) se concentrent dans l’espace latent de l’échelle 54,6 min, cohérent avec leur durée typique de 30–60 min.
- Les pressure drops (très courts) se regroupent compactement dans l’espace latent de l’échelle 51,2 s.
C’est une validation indirecte mais convaincante : la représentation apprise est physiquement meaningful, même pour des signaux rares.
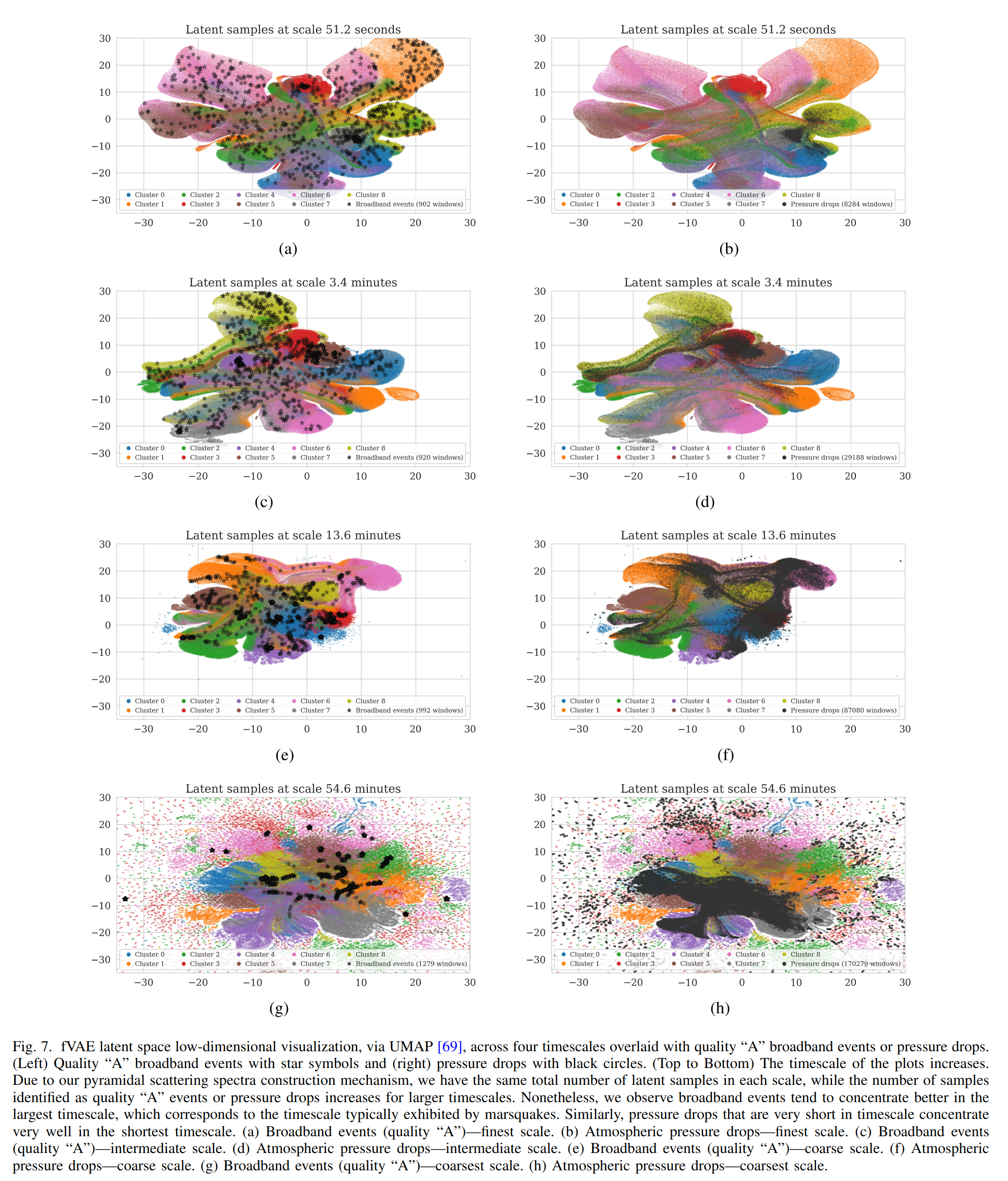
Ce qu’on retient
L’approche proposée dans cet article repose sur une idée simple : avant de séparer des sources, il faut se donner une représentation qui les rende visibles à toutes les échelles. Les pyramidal scattering spectra jouent ce rôle. Le fVAE apprend ensuite à organiser ces représentations en clusters interprétables, et la séparation de sources exploite ces clusters comme prior pour résoudre un problème d’optimisation sans aucune étiquette.
Trois propriétés méritent d’être soulignées :
- Pas d’hypothèse forte sur les sources : contrairement à l’ICA, on ne suppose ni stationnarité, ni gaussianité, ni même le nombre de sources à l’avance.
- Multi-échelle par construction : un glitch de 50 s et une interaction atmosphérique d’une heure sont traités dans des espaces latents distincts, sans se parasiter mutuellement.
- Généralisable : la méthode ne suppose rien de spécifique à Mars. Elle est directement applicable à d’autres missions planétaires comme Europa Clipper, Dragonfly sur Titan, ou le futur Farside Seismic Suite lunaire, où le manque de connaissance a priori sur les sources est encore plus sévère qu’ici.
Références
-
Siahkoohi, A., Morel, R., Balestriero, R., Allys, E., Sainton, G., Kawamura, T., & de Hoop, M. V. (2026). Multiscale Clustering and Source Separation of InSight Mission Seismic Data. IEEE Transactions on Geoscience and Remote Sensing, 64, art. 5902916. DOI : 10.1109/TGRS.2026.3656438 — [code] [data]
-
Bruna, J., & Mallat, S. (2013). Invariant Scattering Convolution Networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(8), 1872–1886. DOI : 10.1109/TPAMI.2012.230
-
Morel, R., Rochette, G., Leonarduzzi, R., Bouchaud, J.-P., & Mallat, S. (2025). Scale Dependencies and Self-Similar Models with Wavelet Scattering Spectra. Applied and Computational Harmonic Analysis, 75, art. 101724. DOI : 10.1016/j.acha.2024.101724
-
Scholz, J.-R., Widmer-Schnidrig, R., Davis, P., Lognonné, P., Pinot, B., Garcia, R. F., et al. (2020). Detection, Analysis, and Removal of Glitches From InSight’s Seismic Data From Mars. Earth and Space Science, 7(11), art. e2020EA001317. DOI : 10.1029/2020EA001317