Analyser ses données trail — Comment lire les données de sa montre
“Ta montre a tout enregistré. Voilà comment regarder tes data sans passer par Garmin ou Strava.”
Après une grosse sortie, le fichier .fit dort sur ton ordinateur (si tu l’as récupéré). Garmin Connect, Strava ou Suunto App te donnent les graphiques standards — profil, FC, allure. C’est bien, mais tu ne peux pas y croiser deux variables, changer les couleurs, zoomer sur un tronçon précis, ou exporter les chiffres bruts.
Ce premier billet te montre comment charger ce fichier en Python et produire tes propres visualisations, sans aller plus loin que quelques lignes de code. C’est la base sur laquelle les deux billets suivants s’appuieront.
Pré-requis
pip install fitparse pandas numpy matplotlib
Le format .fit est le format binaire standard enregistré par Garmin, Suunto, Polar, Coros et la plupart des montres sport. Tu peux l’exporter depuis la page d’une activité sur Garmin Connect (Exporter l’original) ou Suunto App (Exporter). C’est différent du GPX, qui ne contient que la trace GPS sans les données physio.
Juste pour expliquer, si tu découvres Python :
-
fitparseest une librairie qui permet de lire les fichiers.fit, justement -
numpyest une librairie qui permet de réaliser toutes les opérations possibles et inimaginables sur des tableaux et bien plus. -
pandasune autre librairie de manipulation de données de plus haut niveau quenumpy. -
matplotlib, c’est LA librairie de référence pour faire tous les graphiques en Python.
1. Paramètres à renseigner
Quand tu as ouvert le Notebook, tu as un seul bloc à modifier avant de lancer quoi que ce soit. Tout le reste s’adapte automatiquement.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from fitparse import FitFile
# --- À adapter à ta course ---
FIT_PATH = "ma_course.fit" # chemin vers ton fichier .fit
FC_MAX = 185 # ta FC max réelle (bpm) — pas la formule 220-âge
FC_MIN = 47 # ta FC repos (bpm)
# Laisse vide si pas de ravitaillements : RAVITO_KM = []
RAVITO_KM = [19.2, 34.0, 45.0, 58.8, 65.4]
RAVITO_NOM = ["St Christo", "Ste Catherine", "St Genou", "Soucieu", "Chaponost"]
Dans l’exemple, tu auras reconnu les ravitos de la SaintéLyon…
2. Charger le fichier FIT
Un fichier .fit est structuré en messages de types variés — activité, session, tour, et surtout record. Les messages record sont les points enregistrés seconde par seconde : c’est là que se trouvent l’altitude, la FC, la vitesse, etc.
def load_fit(fit_path):
"""Load FIT file records into a pandas DataFrame."""
fitfile = FitFile(fit_path)
records = []
for record in fitfile.get_messages("record"):
row = {}
for field in record:
row[field.name] = field.value
records.append(row)
df = pd.DataFrame(records)
df["timestamp"] = pd.to_datetime(df["timestamp"], errors="coerce")
df = df.sort_values("timestamp").reset_index(drop=True)
df["time_h"] = (
(df["timestamp"] - df["timestamp"].iloc[0])
.dt.total_seconds() / 3600.0
)
return df
df = load_fit(FIT_PATH)
print(df.shape)
print(df.columns.tolist())
Sur une course de 16h à 1 Hz, tu obtiens environ 57 600 lignes. Les colonnes disponibles dépendent de ta montre — les plus courantes sont distance (m), altitude ou enhanced_altitude (m), speed ou enhanced_speed (m/s), heart_rate (bpm), cadence (pas/min), temperature (°C), position_lat, position_long.
Par exemple sur ma montre Suunto, j’ai le résultat suivant :
38262 points enregistrés Colonnes disponibles : ['distance', 'timestamp', 'position_lat', 'position_long', 'heart_rate', 'altitude', 'cadence', 'enhanced_altitude', 'enhanced_speed', 'power', 'speed', 'temperature', 'vertical_speed', 'time_h']
3. Nettoyage minimal
Deux problèmes récurrents à régler avant de faire quoi que ce soit.
Le choix de la colonne d’altitude. Les montres avec altimètre barométrique (c’est souvent la majorité des modèles trail) enregistrent enhanced_altitude, qui est nettement plus précise que l’altitude GPS brute. On choisit automatiquement la meilleure disponible.
La distance monotone. Le GPS peut enregistrer de brefs reculs — quelques mètres — lorsqu’il perd le signal ou fait une correction de position. Si on calcule des vitesses ou des pentes à partir de ces valeurs brutes, on se retrouve avec des différences de distance négatives. np.maximum.accumulate force la distance à ne jamais décroître.
Nouvelles colonnes On va aussi ajouter des nouvelles colonnes comme la vitesse en km/h qui n’est pas renseignée par défaut dans le fichier .fit.
def clean_df(df):
"""Select best columns, enforce monotone distance, compute pace."""
alt_col = "enhanced_altitude" if "enhanced_altitude" in df.columns else "altitude"
spd_col = "enhanced_speed" if "enhanced_speed" in df.columns else "speed"
df = df.dropna(subset=["distance", alt_col]).reset_index(drop=True)
# Distance monotone croissante
df["dist_m"] = np.maximum.accumulate(df["distance"].to_numpy(dtype=float))
df["alt_m"] = df[alt_col].to_numpy(dtype=float)
# Vitesse et allure
if spd_col in df.columns:
v = df[spd_col].to_numpy(dtype=float)
df["speed_mps"] = v
df["speed_kmh"] = v * 3.6
# Allure en s/km — NaN si vitesse quasi nulle (arrêts, pauses)
df["pace_s_per_km"] = np.where(v > 0.5, 1000.0 / v, np.nan)
else:
df["speed_mps"] = np.nan
df["speed_kmh"] = np.nan
df["pace_s_per_km"] = np.nan
return df
df = clean_df(df)
df[["dist_m", "alt_m", "speed_kmh", "pace_s_per_km"]].describe()
4. Résumé chiffré
Avant les graphiques, un résumé en quelques lignes pour vérifier que le chargement s’est bien passé et avoir les chiffres clés sous la main.
Le D+ calculé ici est filtré : on lisse d’abord l’altitude sur une fenêtre glissante, puis on ne comptabilise que les variations dépassant un seuil minimal. Sans ce filtrage, le bruit GPS gonfle le dénivelé de 15 à 30 % selon la montre.
def compute_dplus_dminus(df, dz_thr=0.1):
"""Compute filtered elevation gain and loss."""
alt_smooth = (
df["alt_m"]
.rolling(7, center=True, min_periods=1).median()
.rolling(7, center=True, min_periods=1).mean()
)
dz = alt_smooth.diff()
return float(dz[dz > dz_thr].sum()), float((-dz[dz < -dz_thr]).sum())
dplus, dminus = compute_dplus_dminus(df)
print(f"Distance : {df['dist_m'].max() / 1000:.1f} km")
print(f"Durée : {df['time_h'].max():.2f} h")
print(f"D+ filtré : {dplus:.0f} m")
print(f"D- filtré : {dminus:.0f} m")
if "heart_rate" in df.columns:
hr = df["heart_rate"].dropna()
print(f"FC moy. : {hr.mean():.0f} bpm")
print(f"FC max : {hr.max():.0f} bpm")
Dans mon cas, j’obtiens le résultat suivant :
Distance : 79.5 km
Durée : 10.63 h
D+ filtré : 1898 m
D- filtré : 2410 m
FC moy. : 151 bpm
FC max : 175 bpm
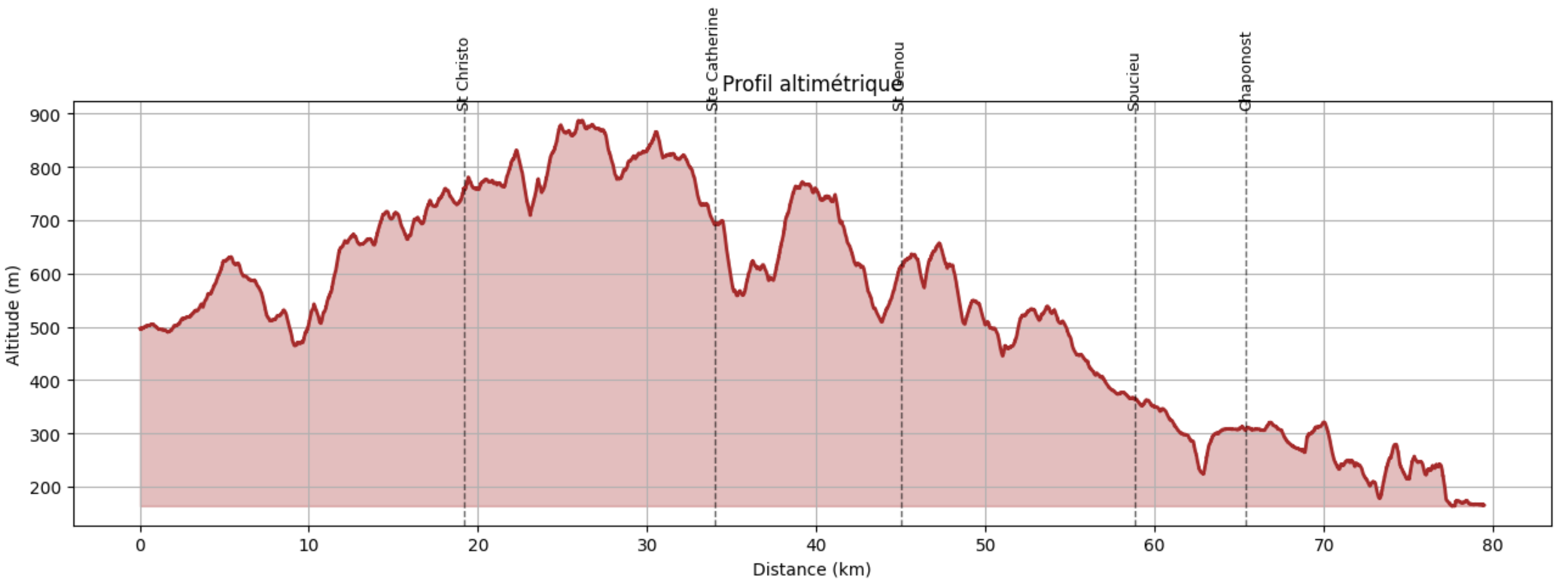
5. Profil altimétrique avec ravitaillements
Le profil de base : distance en x, altitude en y, ravitaillements en pointillés verticaux.
def plot_profil(df, ravito_km, ravito_nom):
"""Plot elevation profile with aid station markers."""
x = df["dist_m"] / 1000.0
y = df["alt_m"]
fig, ax = plt.subplots(figsize=(13, 5))
ax.plot(x, y, color="brown", linewidth=2)
ax.fill_between(x, y, y.min(), color="brown", alpha=0.3)
for km, nom in zip(ravito_km, ravito_nom):
ax.axvline(x=km, color="black", linestyle="--", alpha=0.6, linewidth=1)
ax.text(km, y.max() + 20, nom,
rotation=90, va="bottom", ha="center", fontsize=9)
ax.set_xlabel("Distance (km)")
ax.set_ylabel("Altitude (m)")
ax.set_title("Profil altimétrique")
ax.grid(True)
fig.tight_layout()
plt.show()
plot_profil(df, RAVITO_KM, RAVITO_NOM)
6. Profils colorés — voir les données sur le terrain
C’est la visualisation centrale de ce billet. Le principe : on garde le profil altimétrique comme fond, et on colore chaque point selon la variable qu’on veut observer — FC, allure ou température. L’avantage immédiat sur un graphique temporel : tu vois où sur le parcours quelque chose se passe, pas seulement quand.
Une seule fonction, appelée plusieurs fois avec des paramètres différents.
def plot_profil_colore(df, col, label, cmap="viridis", vmin=None, vmax=None):
"""Plot elevation profile with scatter colored by a data column."""
mask = df[col].notna()
x = df.loc[mask, "dist_m"] / 1000.0
y = df.loc[mask, "alt_m"]
c = df.loc[mask, col]
fig, ax = plt.subplots(figsize=(13, 5))
ax.fill_between(
df["dist_m"] / 1000.0, df["alt_m"], df["alt_m"].min(),
color="lightgrey", alpha=0.5, zorder=1
)
sc = ax.scatter(x, y, c=c, cmap=cmap, s=4, alpha=0.8,
vmin=vmin, vmax=vmax, zorder=2)
plt.colorbar(sc, ax=ax, label=label)
ax.set_xlabel("Distance (km)")
ax.set_ylabel("Altitude (m)")
ax.set_title(f"Profil — {label}")
ax.grid(True)
fig.tight_layout()
plt.show()
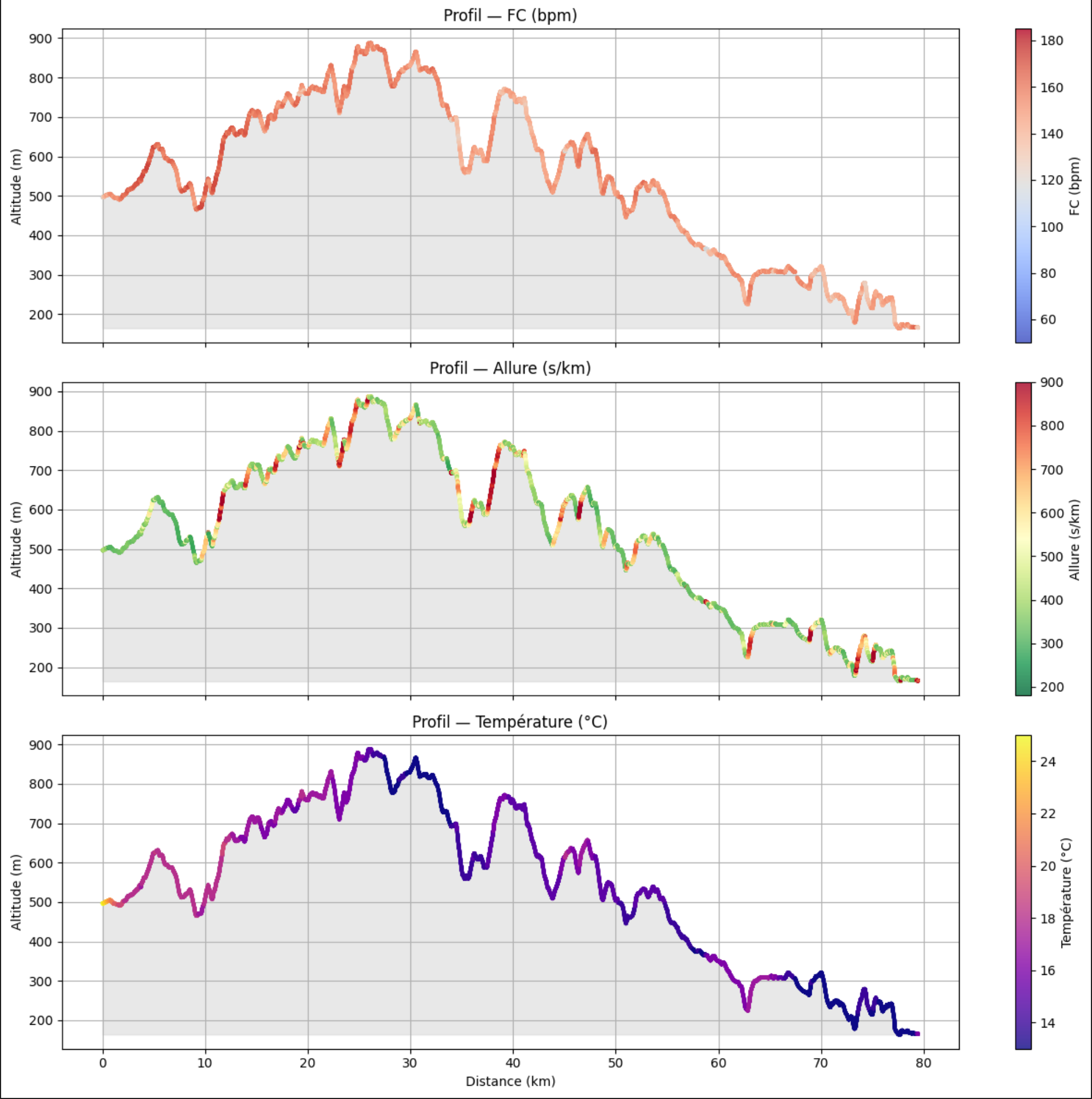
Fréquence cardiaque. La colormap coolwarm donne du bleu aux zones basses (endurance) et du rouge aux zones hautes (seuil, VO₂max). Caler vmin et vmax sur ta FC repos et ta FC max te permet de comparer deux courses différentes sur la même échelle de couleur.
if "heart_rate" in df.columns:
plot_profil_colore(df, "heart_rate", "FC (bpm)",
cmap="coolwarm", vmin=FC_MIN, vmax=FC_MAX)
Allure. L’allure en s/km est une variable inversée — une grande valeur signifie qu’on est lent. La colormap RdYlGn_r (rouge = lent, vert = rapide) est intuitive. Le _r inverse la colormap : sans lui, le vert irait aux grandes valeurs, ce qui est contra-intuitif.
plot_profil_colore(df, "pace_s_per_km", "Allure (s/km)",
cmap="RdYlGn_r", vmin=180, vmax=900)
Les bornes 180 s/km (~5:30/km) et 900 s/km (~15:00/km) couvrent la quasi-totalité des allures trail. Ajuste-les à ta course.
Température. La valeur enregistrée est biaisée à la hausse — elle mélange température ambiante et chaleur du poignet. Elle reste utile pour observer les variations : descente en vallée froide à 3h du matin vs crête exposée au lever du soleil.
if "temperature" in df.columns:
plot_profil_colore(df, "temperature", "Température (°C)", cmap="plasma")
7. Dashboard multi-panneaux
Si tu veux les trois panels alignés en une seule figure, l’option sharex=True est utile : zoomer sur un tronçon dans le premier panel déplace automatiquement tous les autres. Pratique pour inspecter un passage précis.
def plot_dashboard(df, fc_min, fc_max):
"""Multi-panel elevation profiles colored by HR, pace, and temperature."""
variables = [
("heart_rate", "FC (bpm)", "coolwarm", fc_min, fc_max),
("pace_s_per_km", "Allure (s/km)", "RdYlGn_r", 180, 900),
("temperature", "Température (°C)","plasma", None, None),
]
variables = [(c, l, cm, vn, vx) for c, l, cm, vn, vx in variables
if c in df.columns]
n = len(variables)
if n == 0:
print("Aucune variable disponible.")
return
fig, axes = plt.subplots(n, 1, figsize=(13, 4 * n), sharex=True)
if n == 1:
axes = [axes]
for ax, (col, label, cmap, vmin, vmax) in zip(axes, variables):
mask = df[col].notna()
x = df.loc[mask, "dist_m"] / 1000.0
y = df.loc[mask, "alt_m"]
c = df.loc[mask, col]
ax.fill_between(
df["dist_m"] / 1000.0, df["alt_m"], df["alt_m"].min(),
color="lightgrey", alpha=0.5, zorder=1
)
sc = ax.scatter(x, y, c=c, cmap=cmap, s=4, alpha=0.8,
vmin=vmin, vmax=vmax, zorder=2)
plt.colorbar(sc, ax=ax, label=label)
ax.set_ylabel("Altitude (m)")
ax.set_title(f"Profil — {label}")
ax.grid(True)
axes[-1].set_xlabel("Distance (km)")
fig.tight_layout()
plt.show()
plot_dashboard(df, FC_MIN, FC_MAX)
8. Zones de fréquence cardiaque
Un tableau classique, mais calculé depuis les données brutes plutôt que depuis les résumés de la montre. La définition des zones en pourcentage de FC max est la plus répandue en trail — adaptable à d’autres systèmes (FC réserve, zones Garmin à 7 niveaux, etc.).
def compute_hr_zones(df, fc_max, hr_col="heart_rate"):
"""Compute time in HR zones based on %FCmax."""
zones = [
(0.50, 0.60, "Z1 — Récupération"),
(0.60, 0.70, "Z2 — Endurance fond."),
(0.70, 0.80, "Z3 — Tempo"),
(0.80, 0.90, "Z4 — Seuil"),
(0.90, 1.00, "Z5 — VO₂max"),
]
df = df.copy()
df["hr_frac"] = df[hr_col] / fc_max
n_total = df[hr_col].notna().sum()
rows = []
for low, high, label in zones:
mask = (df["hr_frac"] >= low) & (df["hr_frac"] < high)
t_s = mask.sum()
rows.append({
"Zone": label,
"FC min (bpm)": int(low * fc_max),
"FC max (bpm)": int(high * fc_max),
"Temps (min)": round(t_s / 60, 1),
"Temps (%)": round(t_s / n_total * 100, 1),
})
return pd.DataFrame(rows)
if "heart_rate" in df.columns:
print(compute_hr_zones(df, FC_MAX).to_string(index=False))
Ca donne ça par exemple :
Zone FC min (bpm) FC max (bpm) Temps (min) Temps (%)
Z1 — Récupération 92 111 1.0 0.2
Z2 — Endurance fond. 111 129 29.9 4.7
Z3 — Tempo 129 148 170.5 27.0
Z4 — Seuil 148 166 386.9 61.3
Z5 — VO₂max 166 185 42.8 6.8
Conclusion
Je crois que tu as une bonne introduction pour commencer à manipuler tes données. Tu peux aller beaucoup plus loin bien sûr. Là, on ne fait pas mieux que les appli de running.
Le notebook complet associé à ce billet est disponible sur GitHub.
Petit warning
Avertissement : je suis data cientist, pas spécialiste de physiologie de l’exercice. Ce que tu lis ici, c’est le carnet de bord d’un trailer curieux qui aime comprendre ses données — pas un cours magistral. Les sources sont là pour que tu puisses vérifier.
Enjoy Reading This Article?
Here are some more articles you might like to read next: