Analyser ses données trail — Comprendre le terrain
“Le profil altimétrique, tu le connais. On a vu ça dans un précédent billet. Mais est-ce que tu sais à partir de quelle pente tu commences à marcher — et si ce seuil a bougé sur la deuxième moitié de course ?”
Pré-requis
Ce billet suppose que tu as lu et exécuté le billet 1 — le DataFrame df avec les colonnes dist_m, alt_m, speed_kmh, pace_s_per_km doit être en mémoire.
Les paramètres supplémentaires à renseigner :
# Calcul de pente
WINDOW_M = 100.0 # fenêtre en mètres (50–200 selon ta montre)
# Segmentation montées / descentes
UP_THR = +3.0 # pente > +3 % → montée
DOWN_THR = -3.0 # pente < -3 % → descente
MIN_SEG_M = 200.0 # ignorer les segments < 200 m
# Classification marche / course
WALK_THR_KMH = 6.0 # vitesse seuil (km/h)
WALK_THR_CAD = 140.0 # cadence seuil (pas/min)
1. Pente locale robuste
La pente calculée point-à-point — différence d’altitude entre deux lignes consécutives divisée par la distance — est inexploitable. Sur un enregistrement à 1 Hz avec une résolution altimétrique de ~0,5 m, le moindre glitch GPS donne des pentes de plusieurs centaines de pourcents.
La solution : calculer la pente sur une fenêtre glissante en mètres. Pour chaque point, on cherche le point situé environ WINDOW_M mètres en arrière sur la trace, et on calcule la pente entre les deux. Ça correspond à une vraie inclinaison locale, stable et utile.
def compute_slope(df, window_m):
"""Compute local slope (%) over a backward distance window."""
d = df["dist_m"].to_numpy()
z = df["alt_m"].to_numpy()
# Pour chaque point i, trouver l'index j tel que d[j] ≈ d[i] - window_m
j = np.searchsorted(d, d - window_m, side="left")
j = np.clip(j, 0, len(d) - 1)
dd = d - d[j]
dz = z - z[j]
# Éviter la division par zéro en début de trace (dd ≈ 0)
return np.where(dd > 0, (dz / dd) * 100.0, np.nan)
df["slope_pct"] = compute_slope(df, WINDOW_M)
print(df["slope_pct"].describe(percentiles=[0.01, 0.05, 0.5, 0.95, 0.99]))
Le choix de WINDOW_M est un compromis : trop petite (< 30 m), la pente reste bruitée sur les enregistrements GPS basiques ; trop grande (> 200 m), elle lisse les transitions et ne reflète plus la réalité locale. 100 m est un bon point de départ. Sur une montre avec altimètre barométrique, 50 m suffit souvent.
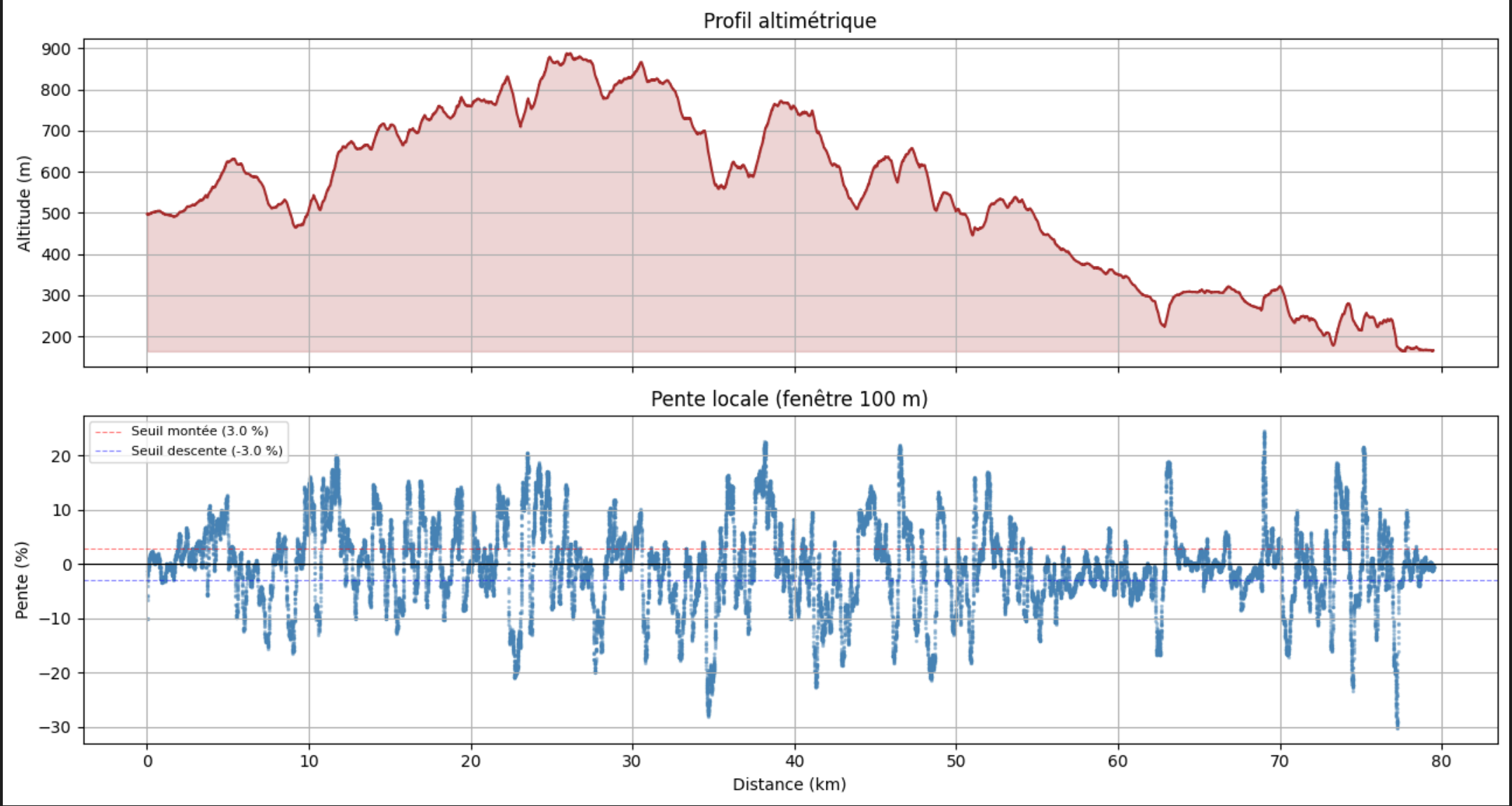
2. Pente sur le profil — vérification visuelle
Avant d’aller plus loin, toujours visualiser pour vérifier que le calcul est cohérent.
fig, axes = plt.subplots(2, 1, figsize=(13, 7), sharex=True)
# Profil altimétrique
axes[0].plot(df["dist_m"] / 1000.0, df["alt_m"],
color="brown", linewidth=1.5)
axes[0].fill_between(df["dist_m"] / 1000.0, df["alt_m"],
df["alt_m"].min(), color="brown", alpha=0.2)
axes[0].set_ylabel("Altitude (m)")
axes[0].set_title("Profil altimétrique")
axes[0].grid(True)
# Pente locale
axes[1].scatter(df["dist_m"] / 1000.0, df["slope_pct"],
s=2, alpha=0.4, color="steelblue")
axes[1].axhline(0, color="black", linewidth=0.8)
axes[1].axhline(UP_THR, color="red", linewidth=0.8, linestyle="--", alpha=0.5)
axes[1].axhline(DOWN_THR, color="blue", linewidth=0.8, linestyle="--", alpha=0.5)
axes[1].set_xlabel("Distance (km)")
axes[1].set_ylabel("Pente (%)")
axes[1].set_title(f"Pente locale (fenêtre {WINDOW_M:.0f} m)")
axes[1].grid(True)
plt.tight_layout()
plt.show()
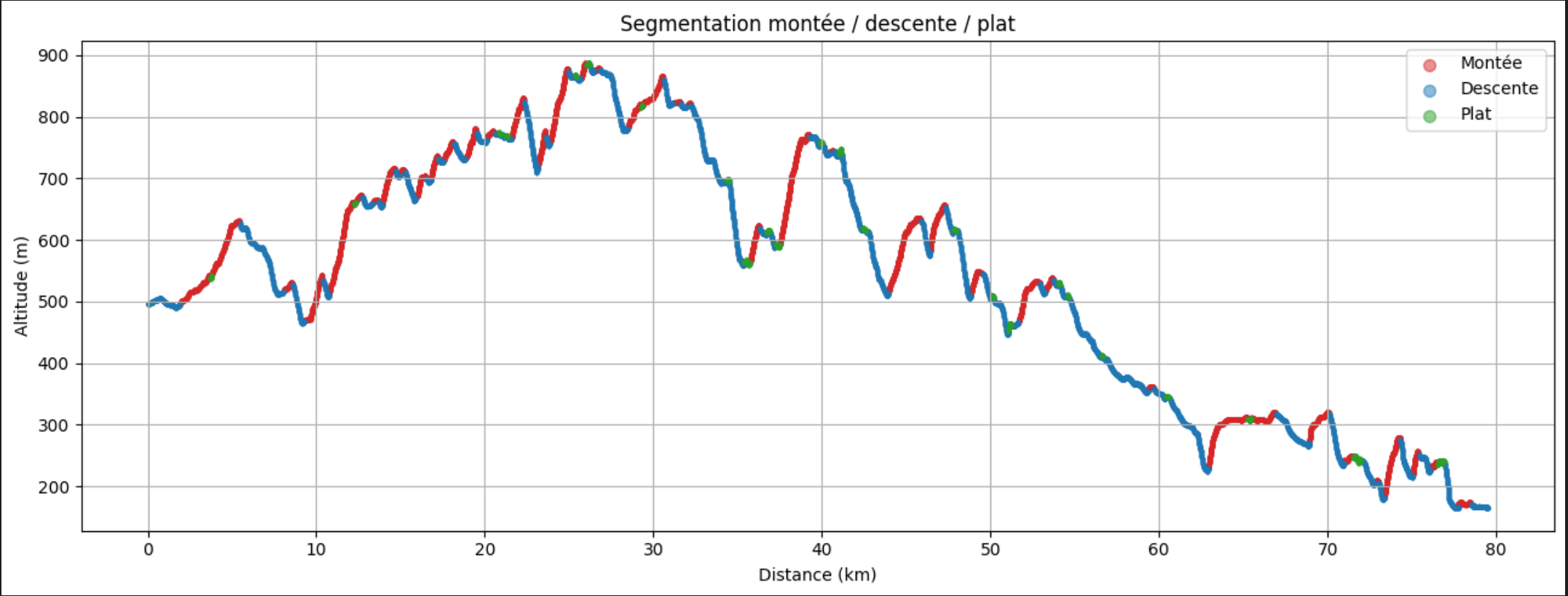
3. Segmentation montées / descentes
On classe chaque point en montée (+1), descente (−1) ou plat (0). Deux mécanismes pour rendre ça robuste :
L’hystérésis. Dans la zone de transition entre +3 % et −3 %, au lieu de basculer immédiatement à 0, on maintient l’état précédent. Ça évite les oscillations rapides autour de la limite (plat → montée → plat → montée → …) sur les faux-plats.
La longueur minimale. Un segment de 50 m classé “montée” parce que deux points consécutifs sont à +5 % n’a aucun intérêt. On supprime tous les segments de moins de MIN_SEG_M mètres.
def segment_updown(df, up_thr, down_thr, min_seg_m):
"""Segment track into uphill (+1), downhill (-1), flat (0) with hysteresis."""
s = df["slope_pct"].to_numpy()
state = np.zeros(len(df), dtype=int)
state[s >= up_thr] = 1
state[s <= down_thr] = -1
# Hystérésis : dans la zone morte, on propage l'état précédent
for i in range(1, len(state)):
if state[i] == 0:
state[i] = state[i - 1]
df = df.copy()
df["ud_state"] = state
df["seg_id"] = (df["ud_state"] != df["ud_state"].shift(1)).cumsum()
seg_len = df.groupby("seg_id")["dist_m"].agg(
lambda x: float(x.iloc[-1] - x.iloc[0])
)
valid = seg_len[seg_len >= min_seg_m].index
df["ud_clean"] = np.where(df["seg_id"].isin(valid), df["ud_state"], 0)
return df
df = segment_updown(df, UP_THR, DOWN_THR, MIN_SEG_M)
counts = df["ud_clean"].value_counts().rename({1: "montée", -1: "descente", 0: "plat"})
print(counts)
# Profil coloré par état montée / descente / plat
colors = {1: "tab:red", -1: "tab:blue", 0: "tab:green"}
labels = {1: "Montée", -1: "Descente", 0: "Plat"}
fig, ax = plt.subplots(figsize=(13, 5))
for state, color in colors.items():
mask = df["ud_clean"] == state
ax.scatter(df.loc[mask, "dist_m"] / 1000.0, df.loc[mask, "alt_m"],
s=3, alpha=0.5, color=color, label=labels[state])
ax.set_xlabel("Distance (km)")
ax.set_ylabel("Altitude (m)")
ax.set_title("Profil — segmentation montée / descente / plat")
ax.legend(markerscale=4)
ax.grid(True)
plt.tight_layout()
plt.show()
4. Classification marche vs course
La vitesse seule ne suffit pas pour distinguer marche et course en trail : on peut marcher à 6 km/h dans une montée raide et courir à 5 km/h sur un faux-plat boueux. La cadence est un meilleur discriminant — elle passe typiquement sous 130–140 pas/min en marche active, quel que soit le terrain.
On combine les deux critères : un point est classé “marche” si à la fois la vitesse est faible et la cadence est basse.
def classify_walk_run(df, walk_thr_kmh, walk_thr_cad):
"""Classify each point as walking (1) or running (0)."""
df = df.copy()
if "cadence" not in df.columns:
print("Pas de cadence — classification impossible.")
df["is_walk"] = np.nan
return df
df["is_walk"] = (
(df["speed_kmh"] < walk_thr_kmh) & (df["cadence"] < walk_thr_cad)
).astype(int)
return df
df = classify_walk_run(df, WALK_THR_KMH, WALK_THR_CAD)
if df["is_walk"].notna().any():
pct_walk = df["is_walk"].mean() * 100
print(f"Temps en marche : {pct_walk:.1f} %")
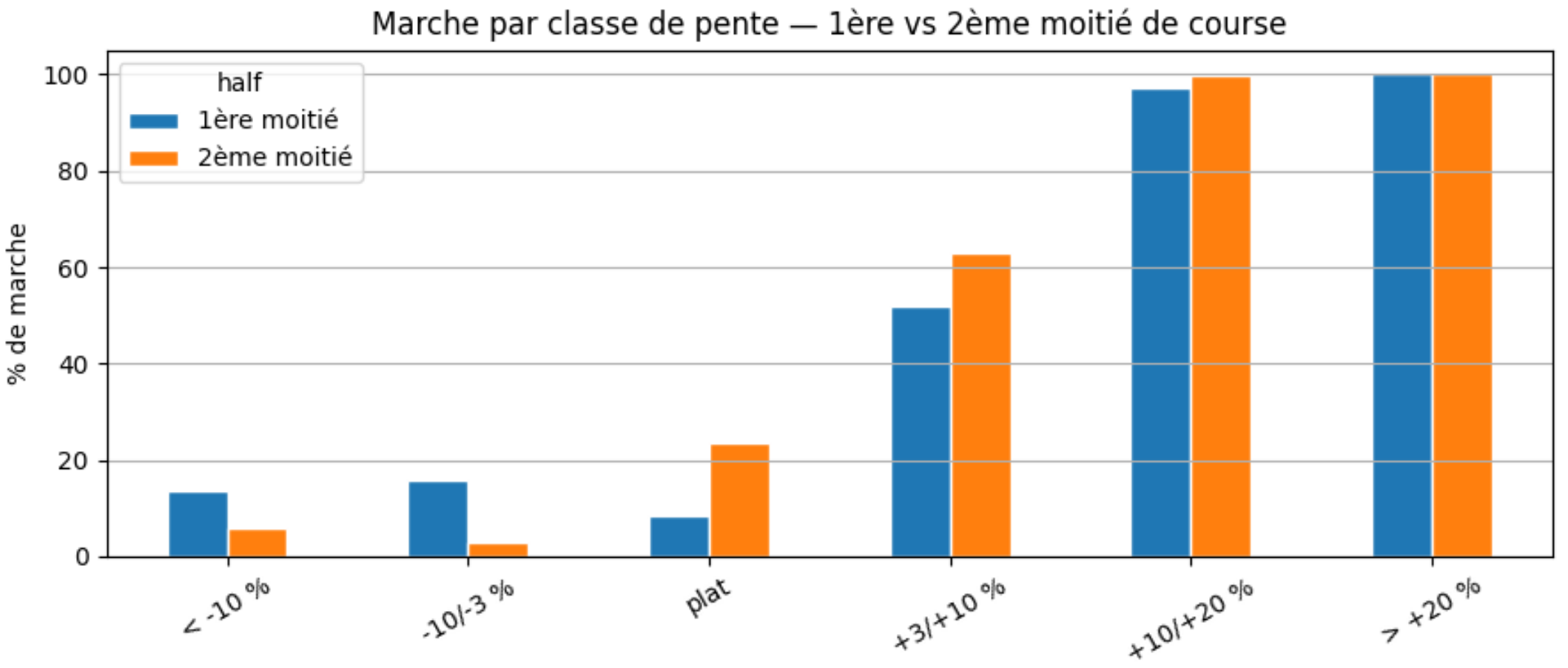
La courbe qui répond à la vraie question. On regroupe par classe de pente et on calcule la proportion de marche dans chaque classe. Ce graphique te montre exactement à partir de quelle pente tu bascules en marche — et en le calculant sur la première et la deuxième moitié de course séparément, tu vois si le seuil a glissé avec la fatigue.
if "is_walk" in df.columns and df["is_walk"].notna().any():
df["slope_bin"] = pd.cut(
df["slope_pct"],
bins=[-30, -10, -3, 3, 10, 20, 40],
labels=["< -10 %", "-10/-3 %", "plat", "+3/+10 %", "+10/+20 %", "> +20 %"]
)
# Première vs deuxième moitié de course
mid_km = df["dist_m"].max() / 2000.0
df["half"] = np.where(df["dist_m"] / 1000.0 < mid_km, "1ère moitié", "2ème moitié")
walk_by_slope = (
df.dropna(subset=["slope_bin", "cadence"])
.groupby(["slope_bin", "half"], observed=True)["is_walk"]
.mean() * 100
).unstack()
fig, ax = plt.subplots(figsize=(9, 4))
walk_by_slope.plot(kind="bar", ax=ax, edgecolor="white")
ax.set_ylabel("% de marche")
ax.set_title("Probabilité de marcher selon la pente — 1ère vs 2ème moitié")
ax.set_xlabel("")
ax.tick_params(axis="x", rotation=30)
ax.grid(axis="y")
plt.tight_layout()
plt.show()
Ca donne ça. Tu la sens passer ta SaintéLyon après Sainte-Catherine ???
5. Grade Adjusted Pace (GAP)
L’allure brute n’est pas comparable entre une montée à +20 % et un plat : courir à 8:00/km sur du +15 % demande beaucoup plus d’effort que sur du plat. Le GAP — Grade Adjusted Pace, allure corrigée du dénivelé — ramène chaque point à son allure équivalente sur terrain plat à même effort.
Le calcul repose sur le polynôme de Minetti et al. (2002), le même que celui utilisé par Strava et Garmin.
def minetti_cost_ratio(slope_pct):
"""Cost ratio relative to flat ground, from Minetti et al. (2002).
slope_pct : slope in percent (e.g. 10 for +10 %)
Returns a multiplicative factor >= 0 (clipped to avoid negatives at extreme slopes).
"""
i = slope_pct / 100.0
cr = (155.4 * i**5 - 30.4 * i**4 - 43.3 * i**3
+ 46.3 * i**2 + 19.5 * i + 3.6)
cr_flat = 3.6 # coût sur le plat (J/kg/m)
ratio = cr / cr_flat
return np.clip(ratio, 0.1, None) # évite les valeurs négatives en descente raide
def compute_gap(df):
"""Compute grade adjusted pace (s/km) using Minetti polynomial."""
df = df.copy()
ratio = minetti_cost_ratio(df["slope_pct"].to_numpy())
# GAP = allure réelle / ratio de coût
# Si ratio > 1 (montée) : GAP < allure réelle (on "court" plus vite à même effort)
df["gap_s_per_km"] = df["pace_s_per_km"] / ratio
return df
df = compute_gap(df)
# Profil coloré par GAP vs allure brute
fig, axes = plt.subplots(2, 1, figsize=(13, 8), sharex=True)
for ax, col, title, vmin, vmax in [
(axes[0], "pace_s_per_km", "Allure brute (s/km)", 180, 900),
(axes[1], "gap_s_per_km", "GAP — allure corrigée (s/km)", 180, 900),
]:
mask = df[col].notna()
sc = ax.scatter(df.loc[mask, "dist_m"] / 1000.0,
df.loc[mask, "alt_m"],
c=df.loc[mask, col],
cmap="RdYlGn_r", s=4, alpha=0.8,
vmin=vmin, vmax=vmax)
ax.fill_between(df["dist_m"] / 1000.0, df["alt_m"], df["alt_m"].min(),
color="lightgrey", alpha=0.3, zorder=0)
plt.colorbar(sc, ax=ax, label=col.replace("_", " "))
ax.set_ylabel("Altitude (m)")
ax.set_title(title)
ax.grid(True)
axes[-1].set_xlabel("Distance (km)")
plt.tight_layout()
plt.show()
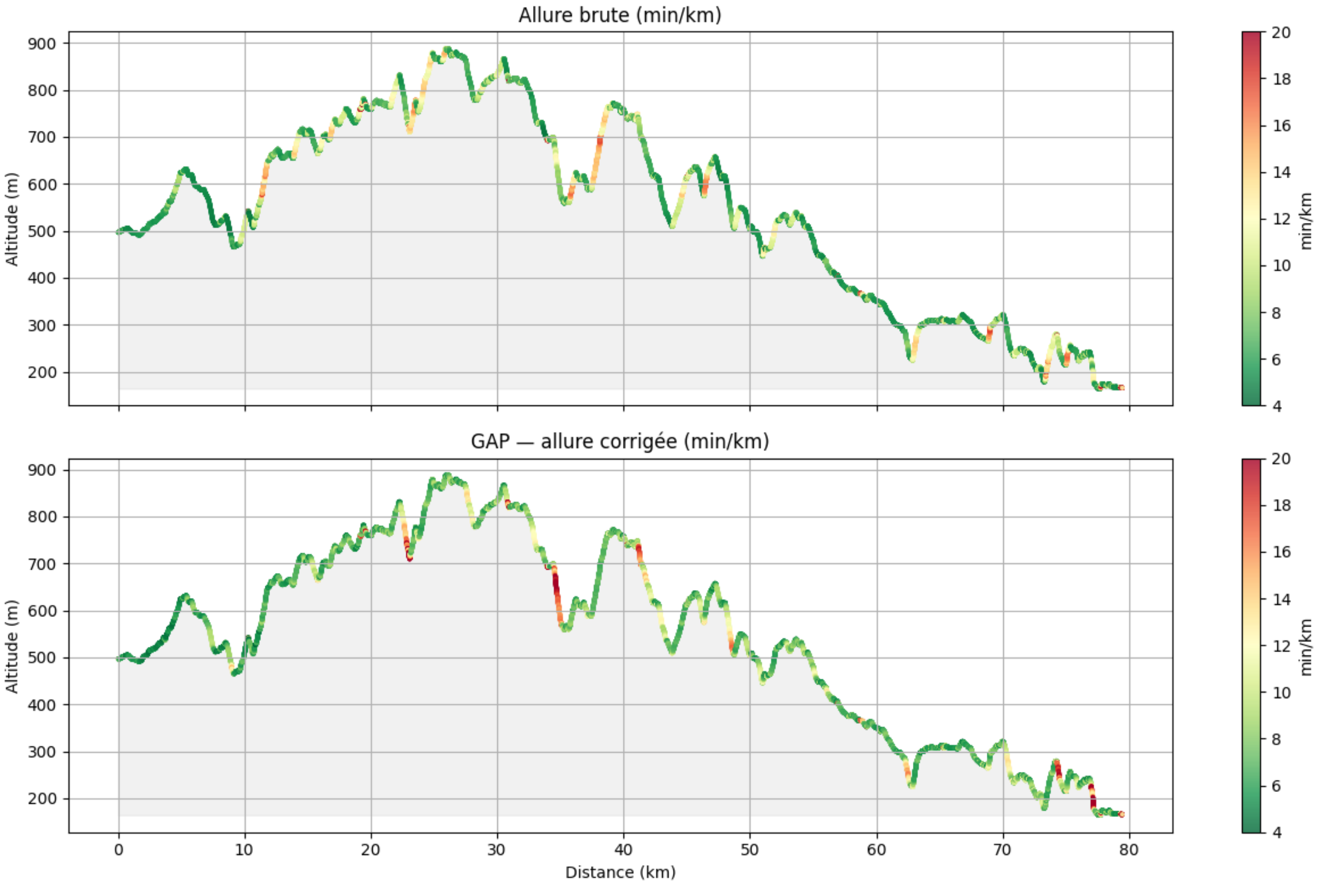
La différence entre les deux panels révèle l’effet du profil sur l’allure. Les zones où le GAP est beaucoup plus rapide que l’allure brute sont les montées raides — là où tu avances lentement mais tu dépenses beaucoup. Les zones où c’est l’inverse sont les descentes à haute vitesse.
6. VAM par section entre ravitaillements
La VAM (Vitesse Ascendante Moyenne, en m/h) est l’indicateur universel de la performance en montée dans les sports de montagne. Elle normalise l’effort d’une montée indépendamment de sa longueur et de son inclinaison : 800 m/h en montée, c’est compréhensible partout, là où “8:30/km à +15 %” demande une conversion.
def section_summary(df, ravito_km, ravito_nom):
"""Compute per-section stats including VAM, GAP, walk ratio."""
bounds = np.concatenate((
[float(df["dist_m"].min() / 1000.0)],
np.array(ravito_km, dtype=float),
[float(df["dist_m"].max() / 1000.0)]
))
labels = []
for i in range(len(bounds) - 1):
a, b = bounds[i], bounds[i + 1]
if i == 0:
labels.append(f"Départ → {ravito_nom[0]}")
elif i == len(bounds) - 2:
labels.append(f"{ravito_nom[-1]} → Arrivée")
else:
labels.append(f"{ravito_nom[i-1]} → {ravito_nom[i]}")
df = df.copy()
df["section_id"] = np.searchsorted(
bounds[1:], df["dist_m"].to_numpy() / 1000.0, side="right"
)
rows = []
for i, lbl in enumerate(labels):
sec = df[df["section_id"] == i]
if len(sec) < 10:
continue
alt = sec["alt_m"].to_numpy()
dz = np.diff(alt)
dplus_sec = float(np.clip(dz, 0, None).sum())
dur_h = float(sec["time_h"].iloc[-1] - sec["time_h"].iloc[0])
row = {
"Section": lbl,
"Dist (km)": round((sec["dist_m"].iloc[-1] - sec["dist_m"].iloc[0]) / 1000, 1),
"D+ (m)": round(dplus_sec, 0),
"Durée (h)": round(dur_h, 2),
"VAM (m/h)": round(dplus_sec / dur_h, 0) if dur_h > 0 else np.nan,
}
if "gap_s_per_km" in sec.columns:
row["GAP méd. (s/km)"] = round(sec["gap_s_per_km"].median(), 0)
if "heart_rate" in sec.columns:
row["FC méd. (bpm)"] = round(sec["heart_rate"].median(), 0)
if "is_walk" in sec.columns and sec["is_walk"].notna().any():
row["Marche (%)"] = round(sec["is_walk"].mean() * 100, 1)
rows.append(row)
return pd.DataFrame(rows)
if len(RAVITO_KM) > 0:
stats = section_summary(df, RAVITO_KM, RAVITO_NOM)
print(stats.to_string(index=False))
Section Dist (km) D+ (m) Durée (h) VAM (m/h) GAP méd. (s/km) FC méd. (bpm) Marche (%)
Départ → St Christo 19.2 749.0 2.34 320.0 375.0 163.0 28.8
St Christo → Ste Catherine 14.8 566.0 2.12 267.0 454.0 156.0 43.2
Ste Catherine → St Genou 11.0 482.0 1.67 288.0 463.0 146.0 49.1
St Genou → Soucieu 13.8 383.0 1.85 207.0 439.0 152.0 35.5
Soucieu → Chaponost 6.6 144.0 0.83 174.0 409.0 150.0 28.2
Chaponost → Arrivée 14.1 383.0 1.81 211.0 448.0 146.0 30.4
La VAM par section est plus parlante que l’allure pour comparer des tronçons de profils très différents. Un tronçon à 700 m/h de VAM avec 50 % de marche est différent d’un tronçon à 700 m/h en course continue — et le tableau te le montre directement.
Conclusion
Tu commences à avoir quelques outils d’analyse intéressants pour ta analyser ta course. Là encore, tu trouves beaucoup de ces calculs dans les applis. Le prochain billet explorera un peu plus les aspects physiologiques.
Le notebook complet associé à ce billet est disponible sur GitHub.
Petit warning
Avertissement : je suis data cientist, pas spécialiste de physiologie de l’exercice. Ce que tu lis ici, c’est le carnet de bord d’un trailer curieux qui aime comprendre ses données — pas un cours magistral. Les sources sont là pour que tu puisses vérifier.
Enjoy Reading This Article?
Here are some more articles you might like to read next: