Prédire son temps en trail — Un problème (vraiment) difficile
“Alors, tu vises combien pour ton prochain trail ?”
La question semble anodine. Elle ne l’est pas. En trail, prédire son temps de course est un problème fondamentalement plus difficile que sur route — et les outils qu’on utilise en général pour y répondre sont bien moins robustes qu’ils ne le laissent croire.
Dans cet article, je passe en revue les principales familles de modèles de prédiction, du plus simple au plus sophistiqué : la formule de Riegel, l’estimation segment-par-segment à partir du modèle de Minetti, les approches de l’ITRA et de Strava, puis quelques méthodes de machine learning. Et je montre qu’ils partagent tous — malgré leurs différences — une même limite que personne n’a encore vraiment résolue.
1. Le modèle naïf : la formule de Riegel (1981)
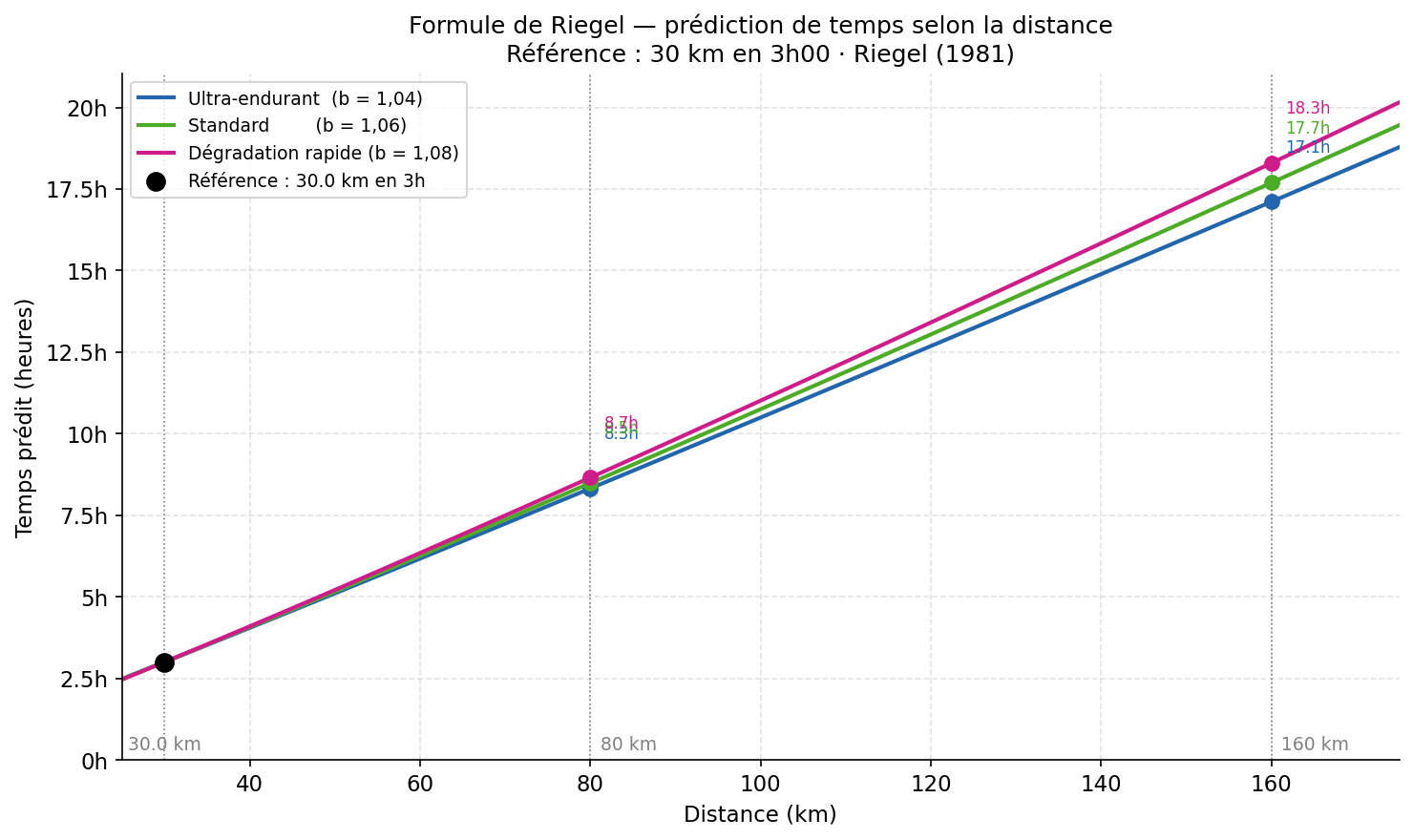
Avant même de parler de trail, regardons le point de départ de presque toutes les prédictions de performance en endurance : *la formule de Riegel.
En 1977, puis dans une version plus formalisée publiée dans American Scientist en 1981, Peter Riegel, ingénieur et coureur, propose la relation suivante :
\[T_2 = T_1 \cdot \left(\frac{D_2}{D_1}\right)^{1{,}06}\]où $T_1$ est le temps réalisé sur la distance $D_1$, et $T_2$ est le temps prédit pour la distance $D_2$. L’exposant $1{,}06$ est une constante empirique ajustée sur des données de records mondiaux à différentes distances (Riegel, 1981).
Cette formule est une loi puissance, ce qui revient à dire que la vitesse décroît avec la distance selon une relation de la forme $v = a \cdot d^{-k}$. C’est simple, c’est élégant, et globalement bien calibré sur une plage de distances allant du mile au semi-marathon chez des coureurs “récréatifs” (Vickers & Vertosick, 2016, BMC Sports Sci. Med. Rehabil., 8, 26).
Ce qu’elle fait bien
Pour comparer des performances sur route à des distances proches — estimer son potentiel sur marathon à partir d’un semi, par exemple — la formule de Riegel reste une estimation honnête et utilisée par des milliers de calculateurs en ligne.
Ce qu’elle ignore totalement
Quatre choses essentielles pour le trail :
-
Le dénivelé. La formule traite tous les kilomètres comme équivalents. Un kilomètre à +30 % n’est pas le même effort qu’un kilomètre plat, et l’exposant 1,06 ne le sait pas. C’est la raison pour laquelle, la formule est plus fiable sur route que sur sentier.
-
La durée de l’effort. La formule est calibrée sur des efforts entre 3,5 et 230 minutes (Riegel, 1981). Au-delà — soit dès que tu cours plus de ~4 heures — elle devient structurellement optimiste. Vickers & Vertosick (2016) le confirment : elle surestime les performances sur ultra.
-
La fatigue cumulée. L’exposant 1,06 est une moyenne de population en conditions “fraîches”. En ultra, le coureur ou la coureuse est un système qui se dégrade en temps réel. Au bout de 10 heures, on est rarement très frais ou fraiche.
-
L’individualité. Certains coureurs et certaines coureuses sont des bêtes d’endurance avec un exposant naturellement proche de 1,04 ; d’autres “explosent” plus vite avec un exposant proche de 1,10. Riegel ne te connaît pas et il y a donc une nécessité d’adapter cet exposant.
En trail, cette formule sert tout au plus de borne inférieure grossière. Elle répond à la question “combien ferais-je si le parcours était plat et si je n’avais pas de jambes à mi-course ?”.
def riegel_time(d2, t1, d1, b):
"""Predicted time at distance d2 from reference (d1, t1)
and exponent b.
Parameters
----------
d2 : array-like Target distance (km)
t1 : float Reference time (hours)
d1 : float Reference distance (km)
b : float Riegel exponent
-> b = 1.06, standard value
-> b = 1.04, Ultra runner
-> b = 1.08, fast degrading performance
Returns
-------
array Predicted times in hours
"""
return t1 * (np.asarray(d2) / d1) ** b
2. Minetti + dénivelé : l’estimation segment par segment
L’idée naturelle pour aller plus loin est d’intégrer le profil altimétrique dans le calcul. C’est là qu’intervient le polynôme de Minetti, dont j’ai déjà parlé ici un article dédié. Rappel rapide :
Minetti et al. (2002, J. Appl. Physiol., 93, 1039–1046) ont mesuré le coût métabolique de la course ($C_r$, en J·kg⁻¹·m⁻¹) sur tapis roulant inclinable, entre −45 % et +45 % de pente, chez 10 coureurs (très) entraînés. Le résultat est un polynôme d’ordre 5 :
\[C_r(i) = 155{,}4\,i^5 - 30{,}4\,i^4 - 43{,}3\,i^3 + 46{,}3\,i^2 + 19{,}5\,i + 3{,}6\]où $i$ est la pente en valeur décimale ($i = 0{,}15$ pour 15 %). Sur le plat ($i = 0$), $C_r = 3{,}6$ J·kg⁻¹·m⁻¹.
L’application pratique : prédire un temps depuis un profil GPS
Tu découpes le parcours en segments de pente approximativement constante. Sur chaque segment $k$ de longueur $d_k$ et de pente $i_k$, on connaît le coût énergétique théorique $C_r(i_k)$. On peut alors estimer la vitesse attendue sur ce segment en posant que le coureur opère à une puissance métabolique cible $\dot{E}$ (en W·kg⁻¹) :
\[v_k = \frac{\dot{E}}{C_r(i_k)}\]Le temps total prédit est alors $T = \sum_k d_k / v_k$.
En pratique, $\dot{E}$ est calibré à partir d’une vitesse de référence sur le plat (ou d’un GAP cible), et le modèle déroule les splits segment par segment. C’est exactement ce que font les calculateurs de trail sérieux et ce que j’ai implémenté dans mon propre outil d’analyse :
def minetti_cost_ratio(slope_pct):
"""Cost ratio relative to flat ground from Minetti et al. (2002)."""
i = slope_pct / 100.0
cr = (155.4 * i**5 - 30.4 * i**4 - 43.3 * i**3
+ 46.3 * i**2 + 19.5 * i + 3.6)
return np.clip(cr / 3.6, 0.1, None)
Le ratio retourné est le facteur multiplicatif appliqué à l’allure sur le plat. Un ratio de 2,0 à +20 % de pente signifie que ce segment coûte deux fois plus d’énergie par mètre qu’à plat — et que, à effort constant, tu devrais aller deux fois moins vite.
Ce que ça apporte par rapport à Riegel
Beaucoup, parce qu’on intègre le profil du parcours. On peut calculer des splits par section, identifier les portions “chères” en énergie, comparer des parcours de dénivelés différents. C’est un vrai progrès.
Ce que ça n’apporte toujours pas
Le modèle de Minetti donne un coût instantané en conditions reposées, pour un coureur moyen. Il ne sait pas :
- que tu es à 60 km et que tes quadriceps sont déjà carbonisés ;
- que tu es toi, et non pas la moyenne de 10 traileurs qui vivent en montagne et qui font 27 sorties par semaine ;
- que la pente à −30 % est en fait du single-track caillouteux et non un tapis.
En d’autres termes, Minetti + profil GPS, c’est un modèle d’ordre zéro sur la fatigue et d’ordre zéro sur l’individualité. Utile, mais encore incomplet.
A cela, il faudrait ajouter le fait que tu ne pars pas dans le sas “élite” (enfin pas moi en tout cas) et qu’un départ de trail est bien souvent laborieux, que tu passes du temps sur les ravitos, que ça peut bouchonner sur certaines portions comme un vendredi soir en sortie de Paris (où sous le tunnel de Fourvière si tu préfères).
3. Quelques outils grand public : ITRA et Strava GAP
3.1 L’ITRA et ses km-effort
L’ITRA (International Trail Running Association) a construit son propre système de normalisation des performances. La brique de base est le km-effort (km-e), défini ainsi :
\[\text{km-effort} = D_{\text{horiz}} + \frac{D^+}{100}\]où $D_{\text{horiz}}$ est la distance horizontale en km et $D^+$ le dénivelé positif en mètres. Un trail de 50 km avec 3 500 m D+ représente donc $50 + 35 = 85$ km-effort. Cette formule est une approximation linéaire du surcoût de la montée, proche de la règle de Naismith utilisée en rando. (Naismith, 1892), et cohérente avec le polynôme de Minetti dans la zone de pentes modérées (+10 % à +25 %).
À partir du km-e, l’ITRA associe un record du monde théorique pour cette distance équivalente (basé sur les records officiels d’athlétisme sur route), puis compare le temps du coureur à cette référence sur une échelle de 0 à 1 000 points :
\[\text{Score brut} = 1000 \times \frac{T_{\text{théorique}}}{T_{\text{coureur}}}\]Ce score brut est ensuite corrigé par un coefficient d’ajustement statistique propre à chaque course, calculé à partir de la base de données ITRA (plus de 8 millions de résultats). Ce coefficient absorbe tout ce que le km-effort ne capture pas : technicité du terrain, conditions météo, altitude, etc. (ITRA, documentation officielle Score de course). L’algorithme précis de ce coefficient n’est pas publié dans la littérature académique — c’est une “boîte noire” statistique.
Ce que ça apporte. Un outil de comparaison inter-courses honnête, une normalisation raisonnée sur dénivelé.
Ce que ça ne fait pas. Prédire ton temps sur une course future. Le score ITRA mesure ta performance passée relative à un record théorique ; il ne modélise ni la dynamique de fatigue, ni ton profil individuel de dégradation sur la distance.
def itra_ratio(slope_pct):
"""Pace adjustment factor implied by ITRA km-effort formula.
km-effort = D_horiz + D+/100
On a 1-km segment at slope i (decimal), D+ = max(0, i)*1000 m.
km-effort = 1 + max(0, i)*10.
Ratio = km-effort / 1 (reference at flat).
Downhill : no adjustment in the ITRA formula (D- ignored).
"""
i = np.asarray(slope_pct) / 100.0
d_plus = np.where(i > 0, i * 1000, 0.0) # D+ en m on 1 km horizontal
km_effort = 1.0 + d_plus / 100.0
return km_effort # = 1 at flat, no downhill correction
3.2 Strava GAP : de Minetti à un modèle data-driven
L’équipe Data Science de Strava a publié sur son blog “strava-engineering” l’évolution de son modèle de Grade Adjusted Pace (Robb, 2017, Strava Engineering Blog). L’histoire est instructive.
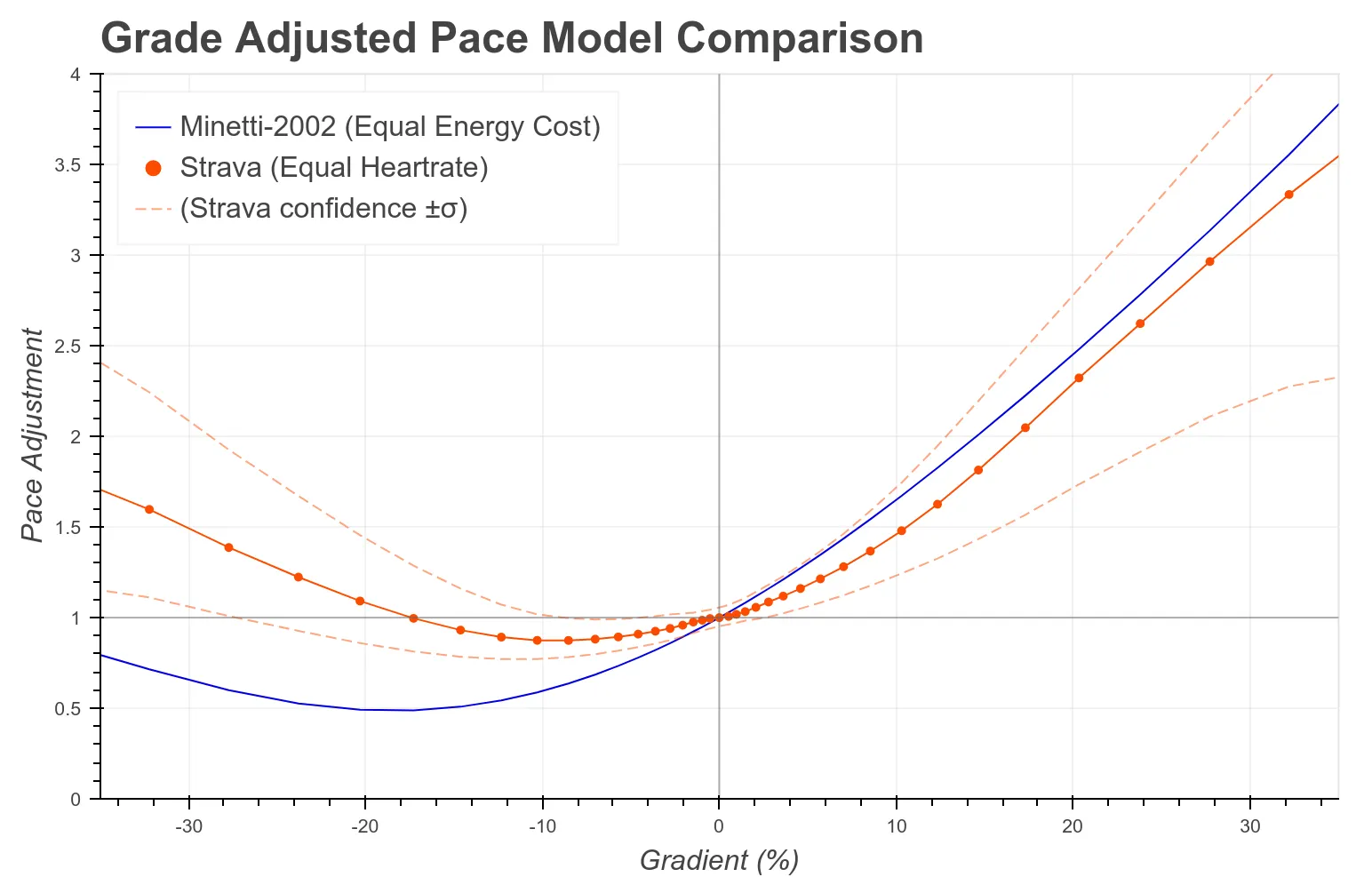
Le GAP Strava était initialement construit sur le polynôme de Minetti (2002) — exactement le même que celui décrit ci-dessus. Strava reconnaît cependant une erreur connue et documentée dans l’article original lui-même : en descente, les vitesses maximales prédites par Minetti dépassent largement ce que les coureurs atteignent réellement. En compétition, les vitesses observées en descente raide peuvent être jusqu’à trois fois inférieures à la prédiction métabolique (Robb, 2017).
Strava, fort d’une quantité hallucitante de données qu’un très grand nombre d’athlètes donnent (en plus de payer leur abonnement), a exploité sa base de données pour recalibrer le modèle en descente, en utilisant la fréquence cardiaque comme proxy de l’effort réel. Le nouveau modèle prédit un ajustement minimal vers −9 % de pente (et non −18 % comme Minetti), et revient à un facteur neutre dès −18 % — reflétant le fait qu’en descente raide, la contrainte n’est plus métabolique mais biomécanique et sécuritaire.
Ce recalibrage est empiriquement plus juste pour l’usage quotidien. Mais il introduit un biais propre : Strava a optimisé non pas pour le coût métabolique réel, mais pour la perception de l’effort par les coureurs de la base Strava, qui sont majoritairement des coureurs route et loisir, pas des ultra-trailers. Le GAP Strava lui-même indique explicitement ne pas tenir compte de la technicité du terrain ni de la difficulté de la descente technique. C’est encore pas parfait, mais c’est déjà mieux.
Ce qui reste commun à Minetti et au GAP Strava. Les deux modèles donnent un facteur d’ajustement identique pour tous les coureurs à une pente donnée. Il n’y a aucune prise en compte de la vitesse du coureur, de son niveau, ni de l’heure de la course.
4. Les exemple d’approche machine learning : TRAP et LSTM
Les limites des modèles “physiques” et des outils grand public ont motivé des approches plus ambitieuses, reposant sur les données de course réelles.
4.1 TRAP (Fogliato et al., 2021)
Fogliato, Oliveira et Yurko, cherchereuses au Department of Statistics & Data Science de l’université Carnegie Mellon, ont publié en 2021 dans le Journal of Quantitative Analysis in Sports le framework TRAP (Trail Running Assessment of Performance). Un nouvelle méthodologie statistique pour l’évaluation de la performance en trail à la fois avant et pendant la course.
Le framework répond à trois questions :
- Quelle est la probabilité que le coureur atteigne le prochain checkpoint ?
- Quel est son temps de passage attendu à ce checkpoint ?
- Quel est l’intervalle de prédiction autour de ce temps ?
Le modèle intègre 26 variables et leurs interactions pour estimer le temps partiel à chaque point kilométrique, le temps total de course, et la probabilité d’abandon. Ces variables comprennent des données telles que — âge, sexe, nationalité — et des informations sur ses participations antérieures à des courses, comme le nombre de courses, le niveau de difficulté et les abandons précédents.
L’algorithme central est un Random Forest, entraîné sur les données des éditions précédentes de l’UTMB, et mis à jour en temps réel au fil des passages aux ravitaillements. Le modèle exploite donc l’historique de course sur le même parcours, et les temps intermédiaires comme features en cours de race.
Ce que c’est en pratique. Un outil de gestion de course pour les organisateurs, et un prédicteur de performance pendant la course. Le modèle est conditionnel aux données du jour J — il nécessite les temps aux premiers checkpoints pour affiner ses prédictions.
Limites. Une limitation centrale est sa dépendance à une base de données spécifique de coureurs testés dans des conditions standardisées de qualité. Cette approche requiert la collecte de données le jour même de la course pour établir une prédiction. Pour un coureur lambda voulant anticiper son temps avant la course sur un nouveau parcours, TRAP n’est pas directement utilisable.
4.2 LSTM sur logs d’entraînement (Dash, 2024)
Une approche complémentaire a été publiée en 2024 dans Sports Medicine International Open (Dash, 2024). L’idée est différente : plutôt que d’utiliser les données de courses, on exploite l’ensemble du log d’entraînement du coureur pour prédire sa performance en compétition.
L’étude introduit une approche généralisée pour prédire les temps de course quelle que soit la distance (du marathon aux ultras), le dénivelé, et le type de coureur. L’intégralité des logs d’entraînement de 15 coureurs — soit 15 686 séances — a été analysée via un réseau de neurones LSTM (Long Short-Term Memory).
Les résultats montrent une précision de 90,4 % pour le LSTM, contre 87,5 % pour la formule UltraSignup et 80 % pour la formule de Riegel, sur un ensemble de test de 60 courses.
Le LSTM est une architecture de réseau de neurones récurrents conçue pour les séries temporelles. L’idée clé est que le log d’entraînement est une série temporelle : la charge d’hier prédit partiellement la forme d’aujourd’hui, qui prédit celle de demain… jusqu’au jour de course. Le LSTM apprend cette dépendance temporelle là où Riegel et même TRAP l’ignorent.
Les features utilisées. Dans cette étude, les variables incluent la distance, le temps, l’allure, et le dénivelé de chaque séance. L’étude note elle-même que l’absence de données physiologiques — fréquence cardiaque, VO₂max, effort perçu — constitue une limitation importante.
Ce que ça apporte. C’est la première approche qui exploite la dynamique temporelle de l’entraînement pour prédire la performance de course. Elle commence à capturer ce que ni Riegel ni Minetti ne voient : l’état de forme relatif du coureur au moment de la course.
Limites: Dash reconnaît le choix du LSTM n’est pas optimal. Et qu’il eu été plus favorable d’utiliser une architecture Transformers. Mais, les Transformers sont très gourmants et nécessitent un volume de données bien supérieur aux 15 686 séances de 15 coureurs disponibles pour généraliser sans surapprentissage. À l’échelle de millions de logs — ce que Strava ou Garmin, ou même Nolio pourraient théoriquement mobiliser — la question redeviendrait ouverte.
5. La limite fondamentale commune : l’absence de modèle de fatigue fiable
Tous ces modèles partagent le même angle mort. Certains l’ignorent complètement, d’autres le contournent partiellement, mais aucun ne le résout vraiment : la dégradation de performance au cours de l’effort.
La relation performance-durée n’est pas une simple puissance
Pour des efforts de plusieurs heures, la dégradation n’est pas homogène. Le coureur à l’heure 1 n’est pas le même qu’à l’heure 5, ni à l’heure 20. Les mécanismes physiologiques en jeu sont différents.
En courte durée, la performance est principalement contrainte par le système cardiovasculaire et la capacité aérobie ($VO{_2}max$, seuil lactique). En ultra-durée, d’autres systèmes s’ajoutent et interagissent : fatigue neuromusculaire, dommages musculaires excentriques (particulièrement en descente), déplétion glycogénique, thermorégulation, déshydratation, et facteurs psychologiques.
Ce que la littérature documente
Vernillo et al. (2014) et Vercruyssen et al. (2016) ont montré une dégradation significative de l’économie de course au fil d’un ultra-trail — c’est-à-dire que pour un même effort cardiovasculaire, la vitesse produite diminue progressivement. Cette dégradation est particulièrement marquée en descente, où les contractions excentriques accumulées génèrent des dommages musculaires documentés (Vernillo et al., 2017, Sports Med., 47, 615–629), là où tu choppes des crampes de la mort !
En clair : la “courbe” qui décrit ta performance n’est pas stationnaire. Elle se déplace vers le bas au fil des heures.
D’ailleurs, quand je compare l’estimation théorique entre Minetti et mes performances réelles sur des 80 km, je constate une dérive quasi linéaire au fil du temps.
Pourquoi c’est le verrou central
Voilà pourquoi aucun des modèles présentés ici n’est vraiment satisfaisant pour l’ultra-trail :
- Riegel prédit un exposant constant. Autrement dit, ta vitesse décroît selon la même loi de puissance à 10 km et à 100 km. C’est faux au-delà de ~4 heures.
- Minetti donne le coût métabolique d’un coureur frais. Il ne sait pas que tu en es à 15 heures de course.
- ITRA absorbe la technicité dans un coefficient statistique, mais ne modélise pas ta fatigue individuelle.
- Strava GAP normalise l’effort instantané, pas l’effort cumulé.
- TRAP conditionne sur les temps aux checkpoints précédents, ce qui capture indirectement la fatigue — mais de façon empirique, sans modèle explicite.
- LSTM apprend la dynamique d’entraînement, mais l’étude de Dash (2024) le reconnaît elle-même : l’absence de données physiologiques en temps réel est une limitation majeure.
Le problème du modèle de fatigue est fondamentalement un problème de modélisation dynamique : il faut décrire comment l’état interne du coureur évolue en fonction de l’effort cumulé, du terrain, de la chaleur, de la nutrition… C’est un système à état continu, avec des interactions non linéaires, et dont les paramètres sont profondément individuels.
Mais je reviendrai sur la modélisation de la fatigue dans la littérature scientifique.
6. Ouverture : vers quoi ça pointe
Les limites qu’on vient de voir pointent toutes dans la même direction. Ce qu’il manque à tous ces modèles, c’est une brique de modélisation individuelle et dynamique de la fatigue — quelque chose qui réponde à : “à ce stade de la course, avec cette charge accumulée depuis le départ, à quelle vitesse ce coureur-ci peut-il raisonnablement courir sur les 5 prochains kilomètres à +20 % de pente ?”
Répondre à cette question nécessite de combiner plusieurs ingrédients :
- un modèle physique du coût énergétique par segment (Minetti comme baseline) ;
- une estimation de l’état physiologique en temps réel (fréquence cardiaque, puissance de course si disponible) ;
- un modèle de dégradation individuel, calibré sur l’historique du coureur ;
- et idéalement, des données sur la nutrition, l’hydratation, la thermorégulation.
Aucun outil public ne fait ça aujourd’hui de manière rigoureuse et accessible. C’est un problème ouvert — et c’est exactement là que le terrain de jeu devient intéressant.
Références
- Riegel, P. S. (1981). Athletic records and human endurance. American Scientist, 69(3), 285–290.
- Minetti, A. E., et al. (2002). Energy cost of walking and running at extreme uphill and downhill slopes. J. Appl. Physiol., 93(3), 1039–1046. DOI
- Vickers, A. J., & Vertosick, E. A. (2016). An empirical study of race times in recreational endurance runners. BMC Sports Sci. Med. Rehabil., 8, 26. DOI
- Fogliato, R., Oliveira, N. L., & Yurko, R. (2021). TRAP: a predictive framework for the assessment of performance in trail running. J. Quant. Anal. Sports, 17(2), 129–143. DOI
- Dash, S. (2024). Win your race goal: a generalized approach to prediction of running performance. Sports Med. Int. Open, 8, a24016234. DOI
- Vernillo, G., et al. (2017). Biomechanics and physiology of uphill and downhill running. Sports Med., 47(4), 615–629. DOI
- Robb, D. (2017). An improved GAP model. Strava Engineering Blog. Lien
- ITRA. Documentation officielle — Score de course et Performance Index. itra.run/FAQ/ItraScore
Petit warning
Avertissement : je suis data scientist, pas spécialiste de physiologie de l’exercice. Ce que tu lis ici, c’est le carnet de bord d’un trailer curieux qui aime comprendre ses données — pas un cours magistral. Les sources sont là pour que tu puisses vérifier.